The free access to this article was made possible by support from readers like you. Please consider donating any amount to help defray the cost of our operation.
AppraiSet: Discussions on a New Art Dataset
Thomas Şerban von Davier, Max Van Kleek, Nigel Shadbolt
Abstract
Artificial intelligence (AI) applications in the arts have gained significant attention, particularly with the advent of generative AI. Researchers have explored AI’s capability to create art autonomously or in collaboration with artists, and AI’s role in curating, classifying, and applying aesthetic metrics to artwork. However, the opaque nature of proprietary algorithms used in these applications presents challenges for understanding AI’s influence on aesthetics. To address this, open-source data and code are essential for investigating how AI can develop its own aesthetic language. This paper introduces AppraiSet, an open art dataset containing evaluative metadata designed to support the field of academic aesthetics. The dataset includes descriptive, interpretive, and financial variables from auction records, providing a foundation for analyzing how AI models might perceive and interpret art. Through a case study using a latent dirichlet allocation (LDA) topic model, this paper demonstrates how AI can be trained to develop its own aesthetic concepts. The paper contributes to the field by sparking further discussion on how machines may influence and reshape traditional aesthetics.
Key Words
aesthetics; artificial intelligence; AI; dataset; LDA topic model
1. Introduction
Artificial intelligence (AI) applications in the arts have been a growing area of interest in computer science since the 1950s, but this interest has surged with the rise of generative AI. Researchers have explored how AI can create art autonomously,[1] or collaborate with artists.[2] Similarly, studies have investigated AI’s ability to curate and classify art by analyzing images,[3] and its role in computational aesthetics, where algorithms apply human-defined aesthetic metrics to images.[4] In both cases, the algorithms engage in aesthetic decision-making, affecting both art scholars and audiences. Lev Manovich argues that AI’s role in culture is expanding, influencing the public’s aesthetic decisions and tastes as a platform curator.[5] However, these aesthetic decisions remain a “black box” to those outside organizations that control proprietary code and algorithms. Therefore, understanding how AI shapes aesthetics requires access to open-source data and code, allowing us to explore how AI may develop its own aesthetic language.
To advance the study of academic aesthetics in the age of AI, scholars and students need access to open-source datasets and exploratory examples that demonstrate how AI interprets aesthetics. This would enable critical analysis of the entire process—from data collection to AI parameters and optimizations—to better understand how machines interpret our aesthetic concepts. This paper takes the first steps toward providing academic aesthetics with a unique art dataset specifically designed for exploring how AI may develop its own aesthetic language.
One of the main challenges in this task is that AI is only as effective as its training data. Any attempt to explore how AI interprets art and develops aesthetic interpretations must begin with the creation of a high-quality art metadata database. While existing art datasets such as wiki repositories and digitized museum collections provide valuable resources,[6] they are often biased toward well-known works and lack essential details like wall text, condition reports, provenance, and meta-descriptions of the artworks. As Mimi Onuoha from New York University and Data and Society, along with Van Miegroet et al., have pointed out, detailed art metadata is often a “missing dataset”—that is, data that is not readily available to the public.[7]
Another challenge is that prior research has heavily focused on using computer vision to analyze art within pre-established parameters. AI applications that generate and analyze images based on existing artwork knowledge are well explored.[8] Ypsilantis et al. review various studies that examine art identification through attributes, supported by instance-level recognition in their datasets.[9] While identifying and creating artworks using AI is fascinating, artworks are rarely disconnected from their social and financial contexts, which often inform aesthetic interpretations.
Given these challenges, this paper presents AppraiSet, one of the first open art datasets containing evaluative metadata, available for academics and researchers interested in how aesthetic details can be captured in data and used to train AI. The dataset compiles information from published auction results listed on major auction house websites. It includes descriptive variables (such as artist, year, medium), interpretive variables (such as condition, provenance, exhibition history), and financial variables (such as estimated value and final sale price). This paper outlines the justification for this dataset that over recent years has evolved alongside art and machine learning research. Following this, we describe the data collection, cleaning, and presentation process, making it accessible for open and collaborative use.
To demonstrate the potential of this dataset, we present a case study using a latent dirichlet allocation (LDA) topic model, a natural language processing (NLP) technique that identifies distinct topics within text data by recognizing patterns and grouping similar concepts.[10] This case study illustrates how AI can begin to develop its own aesthetic language based on the data provided. It opens the discussion on how AI’s aesthetic decision-making processes can be studied and refined within academic aesthetics. This paper has two primary contributions:
-
The release of AppraiSet, an academic dataset that art experts can build upon and refine.
-
An educational example of how AppraiSet can be applied using an LDA topic model to explore how AI develops its own aesthetic language.
The paper concludes with a discussion of the broader implications of this work, considering how machines might form aesthetic interpretations of art and whether these interpretations extend or transform existing approaches to aesthetics.
2. Related work
This section outlines the context of related work that gives rise to three primary justifications for creating and managing this dataset. The first is a continuously growing interest in computationally analyzing artworks. The second is to further the initiative for open and accessible data. The final justification outlines the significant potential data from auction lots and provides researchers with an AI with high-quality training data.
2.1. Growing interest in art data
Complex computational algorithms entered the art world as early as the 1950s and generally can be grouped into two categories of programs: creation and classification of art.
Starting with the creation side, Hiller and Isaacson’s work with the Illinois Automatic Computer (ILLIAC) and computer-generated music was the first step in what is now known as computational creativity.[11] Hiller and Isaacson explored how their massive computer at the University of Illinois could handle “nonnumerical” data, specifically music notes. In the 1960s, Vera Molnar, Frieder Nake, Michael Noll, and Georg Nees were pioneers in using computers to print graphics and geometric expressions.[12] It is this early work that has paved the way for advances in computer graphics, digital art, and more recently AI-generated art. The most recent example of a growing interest in art and machine learning has been the release of DALL-E, Midjourney, and Adobe’s Generative Fill.[13]
When it comes to classification and processing of art, Herbert Simon and Marvin Minsky, two central computer science and AI thought leaders, contributed to discussions on computational creativity.[14] Their early work looking at patterns in music data looked into what it meant for computers to recognize unique creative work. Fast forward a few decades to MIT’s MosAIc algorithm and the work by Thread Genius, and AI became capable of visually interpreting art and identifying similarities between art pieces.[15] MosAIc specialized in connecting visual characteristics of famous museum works of one culture with similar visuals in works by another culture. On the other hand, the AI of Thread Genius focused solely on matching visual characteristics and recommending similarities. The work of Thread Genius was valuable enough for Sotheby’s to acquire the team and integrate them into the auction house’s product team.[16] The acquisition serves as one example where computation and machine learning (ML) work have been integrated into the financial bodies of the art world.
Since the 2018 acquisition, research continues to explore the rich data that can be found in connection to art. Previous iterations of the NeurIPS Datasets and Benchmarks track has also seen its fair share of papers interested in exploring art data in greater detail. The introduction of the Met dataset and art sheets for art datasets, among others, is a sign of an active community of ML researchers interested in processing the complexities of artworks.[17]
The contributions of available big datasets, computing power, sophisticated algorithms, and the availability of online markets are beginning to shape the financial and social networks of the art world. This digital evolution is exemplified by the Blouin Art Sales Index and the Artnet Price Dataset, two large online datasets marketed to art experts as research tools.[18] These two datasets also provide the second justification for this paper.
2.2. Availability and obstacles to art data
While two similar datasets exist, Mimi Onouha’s claim that information about art metadata is missing is still legitimate due to limited accessibility, as discussed below.
The Blouin Art Sales Index, offered by Blouin ArtInfo, searches and visualizes data regarding sale records of specific pieces or artists. A unique feature of The Blouin Art Sales Index is the Interactive Market Insights tool, which allows users access to high-quality data visualizations alongside their search results. It is an incredibly effective tool used by multiple researchers investigating various topics.[19] However, this information is only available through Blouin ArtInfo’s subscription plan. Moreover, the subscription plan only provides restricted access to the dataset; for example, one can conduct a maximum of 200 database searches and receive up to 20,000 results. Therefore, any attempt to select a large sample from this database, as needed to support computational models, becomes costly and arduous.
The Artnet Price Database is comparable to The Blouin Art Sales Index. The database includes information about particular galleries and the primary sales data for individual pieces and artists. Unlike The Blouin Art Sales Index, The Artnet Price Database does not emphasize data visualization. However, it focuses on the quality of the available queries and search tools by highlighting its relationship with galleries and art dealers. Nonetheless, this database is also subscription-based and limits the data a user can request. As both Artnet and Blouin have business incentives to restrict access to information, the only way for researchers to explore large-scale art data is to compile a database.
Both tools support Onouha and Van Miegroet et al.’s claim that information regarding artists and art metadata in a dataset is difficult to access.[20] Seeing the lack of access to an existing open dataset regarding financial art valuation and appraisal, we were motivated to develop our research using methods that would ensure understandable and rigorous data integrity.
2.3. Justifying appraisal data
To understand how AI and aesthetics interact, we need high-quality art data to allow an AI to explore the information. This data is not just digitized scans of the artwork, as many museums tend to do with their collections.[21] Instead, the data needs to be rich in various variables more directly tied to the topics covered in aesthetics. Therefore, we built AppraiSet on information from publicly listed art auction lot results. This is advantageous for an AI for various reasons. First, auction lots provide a large sample of data to draw. Even with the impact of the COVID-19 pandemic, the art market’s valuation was at 61 billion USD, with an estimated 36 million transactions in 2021.[22] Second, appraisers are art experts, and their records use the language of aesthetics to describe the pieces. Third and finally, auction lots include quantifiable metrics in the form of art valuation.
While some may argue art valuation via appraisal differs from aesthetic valuation,[23] others argue it is increasingly difficult to separate the two concepts.[24] Modern approaches to art analysis rely on quantitative financial values for the basis of measurement and comparison.[25] Furthermore, art value in the form of financial details is a useful way to quantize art that has been around for far longer than AI has been in the discussion. As a result, we have kept those variables within the dataset should they help explore precisely how an AI may approach understanding and interpreting the artistic pieces. While the algorithm and the dataset will not necessarily establish a relationship between aesthetics and art value in this paper, this new way of looking at art may add color to the ongoing debate among art scholars.
In addition to showing an algorithm in practice, we are offering access to a dataset as an initial step in consolidating high-quality art data that is not reliant on images and scans of artwork. Our data comes from credible auction houses and contains full appraisal details, allowing an AI to look at art as more than just a piece of work; it also includes information about the artist, condition, and provenance of the piece.
3. Methods for dataset compilation
This section outlines how we built the dataset using web scraping and data compilation. Our work followed a set of globally recognized variables and gathered data from online public auction lots.
3.1. Variables
Art professionals document and analyze art using clearly defined variables and classifications. A standardized set of these quantitative and qualitative variables for each transaction forms the basis of the field of art appraisal. Mary Rozell, Global Head of the UBS Art Collection, detailed the specifics of an appraisal in her book on art collection.[26] Sotheby’s also presented a mini-series on YouTube providing a detailed overview of these variables.[27] Our initial dataset implementation incorporated these industry experts’ shared variables and classifiers.
We added additional variables to ensure the dataset is robust enough to handle various cross-sectional explorations into what variables inform art analysis. Our additional variables fall primarily into information about the artist and transaction details. Table 1 outlines the variables in detail from the various groupings.
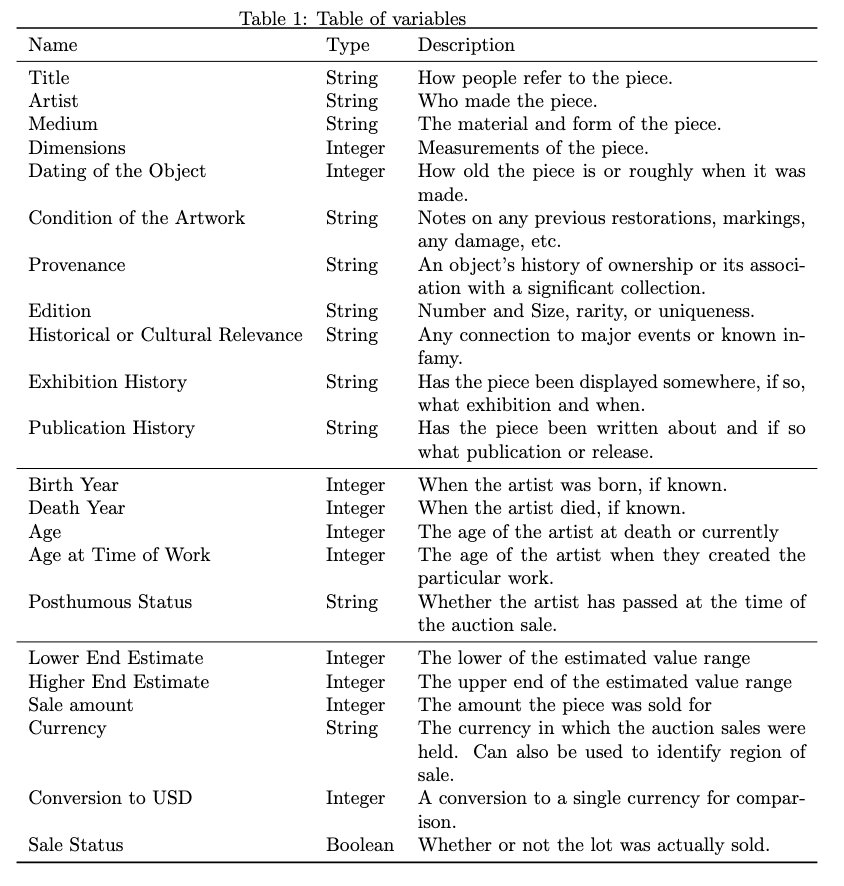
Industry standard. These are the essential eleven variables industry experts describe to develop an estimated value for an art piece. It is essential to recognize that no variables specifically are associated with the visual components of the piece. In other words, this dataset does not capture a visual representation of the art piece. The primary motivation behind this is to establish an appraisal process that is general enough for an AI to consistently evaluate artworks of all aesthetic types.
Artist details. These details include each artist’s birth and death year and their age calculation. The age is calculated to the current year if there is no death year. There is an additional measure of the artist’s approximate age when making each art piece. Since the dataset is organized by artwork, the details regarding the artists’ ages can be repeated, but what often sets it apart will be their age when creating a piece of art. Another variable we included was to see whether the artwork was sold after the artist’s death. There may be an interest in understanding the impact of an artist’s legacy on the evaluation of their artwork.
Financial details. The auction house sites scraped to create the dataset will provide the estimated value associated with each piece. These values and the currency of the financial value are included. An additional variable signifies whether the specific art piece was sold with all the associated variables. This variable serves to check whether a particular financial estimation is aligned with the public’s expectations. The final sale price, or lack thereof, is converted alongside the estimated values to a single currency for consistency and ease of comparison. We maintained the financial details in the dataset for future research. As mentioned, aesthetic value and market value are oft contentious subjects,[28] and more data may add further insights into the debate.
As a result of these additional variables, each art piece within the dataset had at least eleven base variables, with an additional eleven expanded variables. To reiterate, none of the variables considered the visual details of the piece. This was carried over from the guidance of the subject matter experts, who did not include piece details as part of their appraisal process.[29] Like an appraiser who needs to value many pieces of different styles, an AI interpreting aesthetic language also needs to be as general as possible. Therefore, the current dataset contains no visual representations of the works.
3.2. Data collection
We collected data from past public auction records to provide well-formatted art metadata. Unlike galleries, major auction houses post their lots online, available for all to explore. Furthermore, these details are only about the auction lots and do not include any information regarding audience members or art purchasers. This adherence to anonymity by the auction houses allows us to ensure that our data does not handle private or sensitive information. Through a custom-built web scraper and various data cleaning functions, we accumulated 31,000 auction lots rapidly. When deciding which lots to scrape, we limited it to physical art pieces (no NFTs or other digital works) and no major interior design auction sales. Our filtering decision was relatively successful in limiting the data collection to visual art pieces such as prints, multiples, paintings, photography, statues, and sculptures. Our program collected all the significant variables and classifiers described in the previous section with these limitations in mind. The standardized webpage layout aided our gathering of each lot in the public auction records. We intend this to be a live dataset; data collection and cleaning will continue beyond the current number of collected auction lots.
3.3. Data cleaning
The initial dataset required substantial cleaning. Data cleaning was necessary due to the variability of different pieces and auction locations. For example, some pieces had multiple measurements due to the inclusion of the frame, while other pieces sold in Paris had details repeated in both English and French. Similar issues arose with auctions held in Hong Kong and Shanghai. Another challenge was handling the inconsistency of details regarding text-based variables such as condition reports, provenance, and historical significance. These variables are non-quantitative accounts of the piece’s history and current state and are of variable length and detail across the auction lots. As these contain the most instances of aesthetic language and details of the art, we ensured they were cleaned and centralized in a text cell for AI training and analysis. We manually verified the data before dividing it randomly into a training and testing set.
3.4. Limitations of the dataset
Alongside submitting the clean dataset, it is essential to include a short description of the dataset’s limitations. One of the most glaring limitations is the source of the data. We were limited to publicly available auction lots posted by major auction houses. Therefore, this dataset does not include information from museums or art historians. This data can improve as more art institutions digitize their text and variables.
Another limitation is the absence of a comparable, accessible dataset. As explained in section 2, there are datasets on art pieces that are financially restricted. This has led our research group to develop this dataset and understand the ideal composition of art information through a process of trial and error. This lack of external validation is a strong motivator for us to open the dataset and initiate a collaborative process with other academics and individuals in the art world, ensuring it becomes a truly meaningful collection of information.
3.4.1. Ethics considerations on the dataset
The limitations relate to the dataset’s ethical considerations and future applications. The dataset primarily consists of sales from major auction houses, resulting in inherent bias due to its narrow focus on a privileged and affluent segment of the global population. These auction house will remain anonymous as collecting their data is not encouraged. Therefore, the dataset will be made available upon request and ensured it will not be used for commercial purposes to avoid any licensing issues. Additionally, the dataset may not adequately represent new artists or those from underrepresented backgrounds, as it likely favors established artists with a significant art appraisal history favored by the auction houses. By inviting collaborators to review this dataset will shed light on potential biases in the types of art and artists traded at public auctions, leading to improved processes.
We recommend expanding the variables and data sources to address the ethical challenges associated with the auction data and the utilization of this dataset. Collaboration with galleries and museums will introduce a new category of high-quality art data. Similarly, incorporating details about the artists’ gender, ethnicity, and sexual identities ensures a more inclusive representation across various groups within the dataset and the art it encompasses.
3.5. Dataset details
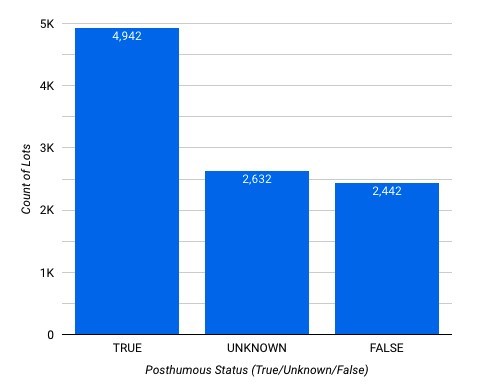
We selected a subset of the overall dataset for the case study in section 4. The verified data contains 10,016 individual auction lots. These auction lots represented 4,329 individual artists, with an average age of 77.22 years. The average age of the artists when creating their art pieces was approximately 48.53 years. The artworks ranged from early historical pieces estimated from 1200 B.C.E. to contemporary art made in 2021. As a result of this distribution of historical to modern artwork, a handful of artists were unknown or craftspeople whose names have been lost to history. Therefore, while there was data regarding the artwork and financial details of the auction, there was limited information regarding the artist’s details. Figure 1 shows the distribution of posthumous to living and unknown artists.
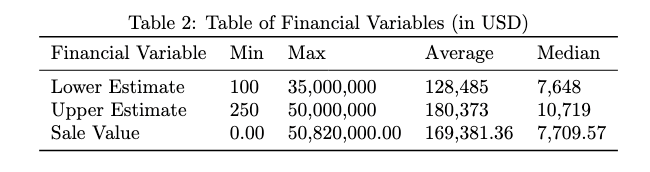
In addition to details regarding the artists, we included information about the various financial variables in the dataset. Table 2 shows the breakdown of minimum, maximum, average, and median values for the converted financial values in USD. Notably, we have the difference between the average and median sale value caused by high-value auction items that pulled the average well above. Furthermore, approximately 20 percent of the auctions did not result in a sale, which led to sale values of 0.00 USD, which we can explore in future work as missing data through a variation of Heckit models.[30]
4. Case study: topic modeling with AppraiSet
Having outlined AppraiSet, we now present a case study exemplifying the dataset’s usability while demonstrating how an algorithm may process aesthetic language. For this example, we use an LDA topic model. Abera Yilma et al. define an LDA model as a tool for drawing abstract topics from an extensive collection of text data to explore the less obvious subject matter contained within the data.[31] In other words, latent dirichlet allocation (LDA) models are algorithms that classify data points into “topics” based on the patterns of associated words and phrases in the text. Using this model, we explore exactly how an algorithm may develop its classification of artworks using the language of art experts. Previous work on LDA models and art have handled smaller datasets without the language of aesthetics. Therefore, this will be an early step in exploring how an algorithm may process aesthetics on its own. The remainder of this section details how we established and evaluated our LDA model using the training set of AppraiSet.
4.1. Building the model
We built our LDA model using the AppraiSet training data subset of 8,506 artworks. Since this paper focuses on exhibiting how an AI may develop its own aesthetic associations, we had to drop some of the columns to trim down to only the core qualitative text data points. The final variables we included were the title, artist name, medium/materials, condition, provenance, edition, historical or cultural relevance, exhibition history, publication history, and currency. For the model to efficiently process all the text contained within these different variable categories, we concatenated all of the text into one large text document for each work. While cleaning the data, our previous concatenation accelerated our task of creating one “all attributes” section within the dataset. With the data for each auction lot consolidated as a single text document, we could perform the proper pre-processing. This pre-processing involved setting up custom stop words such as auction, lot, condition, and report, among others. Stop words are specific words that are so universal in a dataset that their inclusion in a text description of an artwork likely will not help differentiate it from any other artwork data points.[32] We highlighted our unique stop words in the pre-processing stage. We also removed punctuation, established bigrams and trigrams, and lemmatized and ensured the text was all lowercase before developing the model using the popular gensim library.[33]
4.2. Evaluating the model outputs
We evaluated the performance of AppraiSet by comparing its trained LDA model to a model from previously published research, specifically the work of Abera Yilma et al., which serves as our baseline for evaluation.[34] Their study was chosen due to its similar approach in using art metadata to train language models. To assess the effectiveness of our topic model, we analyzed both the pyLDAvis output [35] and the coherence values generated from our dataset. The pyLDAvis output provides a visual representation of topic distribution across the dataset, showing the salience, frequency, and relevance of key terms that define each topic. Topic distribution refers to how distinct the algorithm perceives each topic to be, based on the terms and language used.[36] Each term in the dataset is assessed for its salience (how useful it is in identifying topics), frequency (how often the term appears), and relevance (how exclusive the term is to that particular topic).[37] Coherence values, on the other hand, measure how semantically related the words within each topic are. A higher coherence value indicates better topic formation.[38]
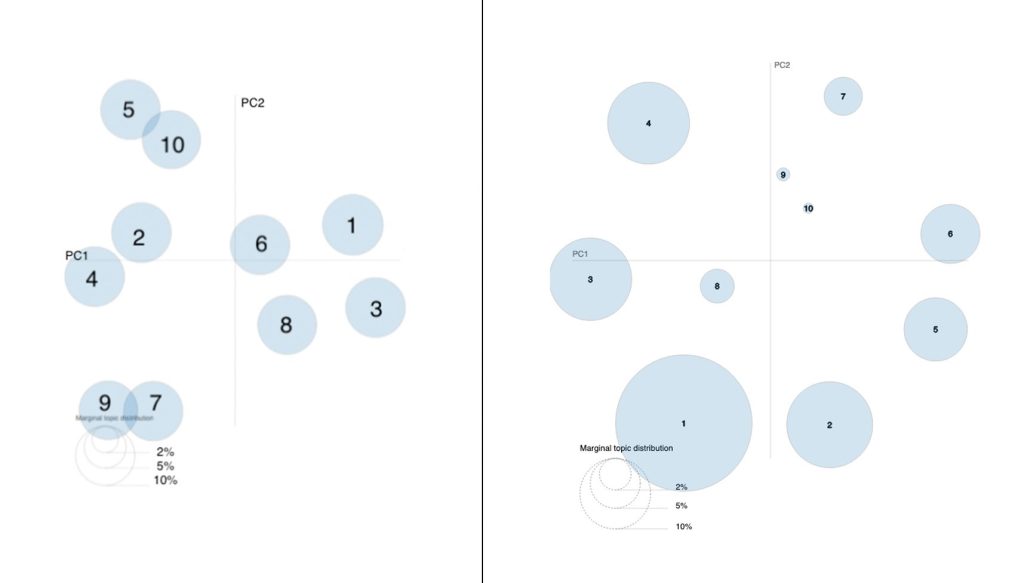
We begin our comparison with the baseline by examining the distribution of ten topics on the pyLDAvis plot. Figure 2 displays our ten-topic distribution alongside the results from Abera Yilma et al. Our model shows distinct separation between topics, with no overlapping groups. The topics are distributed across the chart without excessive clustering, demonstrating that the model interprets the artworks in each topic distinctly, with clear separations reflected in the unique language used to describe them.
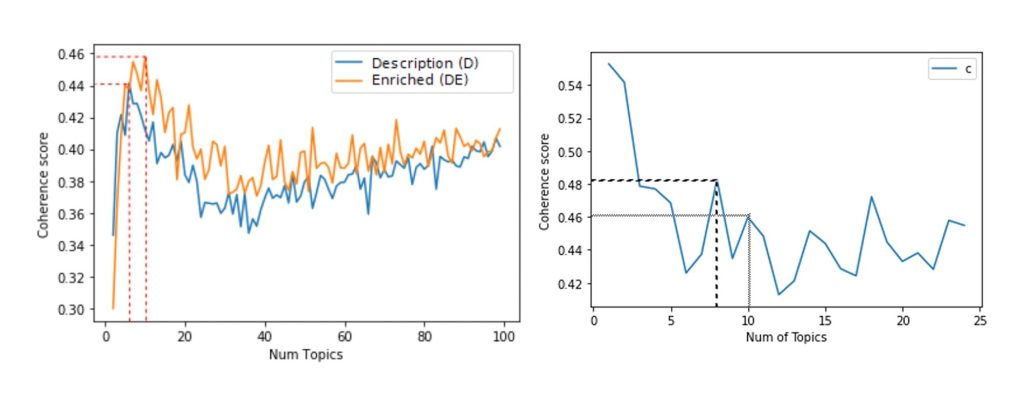
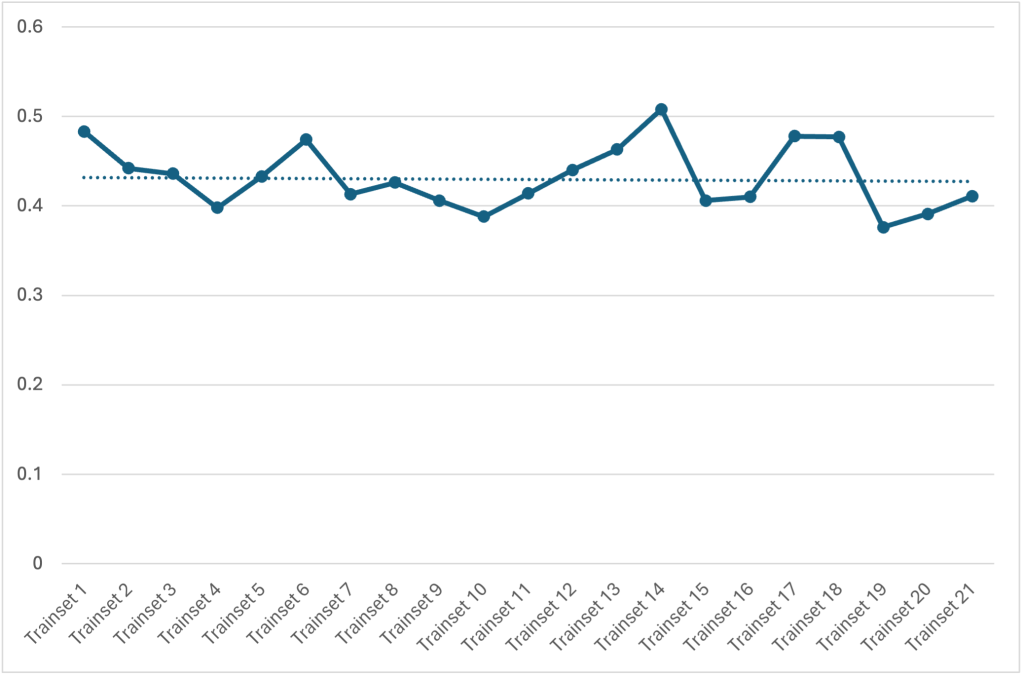
For the initial model, we pre-selected ten distinct topics. At this level, our model’s coherence value is comparable to that in Abera Yilma et al.’s plot, around 0.46 (Figure 3). However, when running the model with eight topics, our coherence value increases slightly to over 0.48. Moreover, our coherence values remain consistently higher even when the number of topics is increased to as many as twenty-five. We repeated this analysis with different splits of the dataset to ensure that the coherence of topics remained stable regardless of how the training and test data were divided. The coherence values for eight topics across different test splits are shown in Figure 4, with values ranging from 0.376 to 0.508, consistently outperforming the baseline on average.
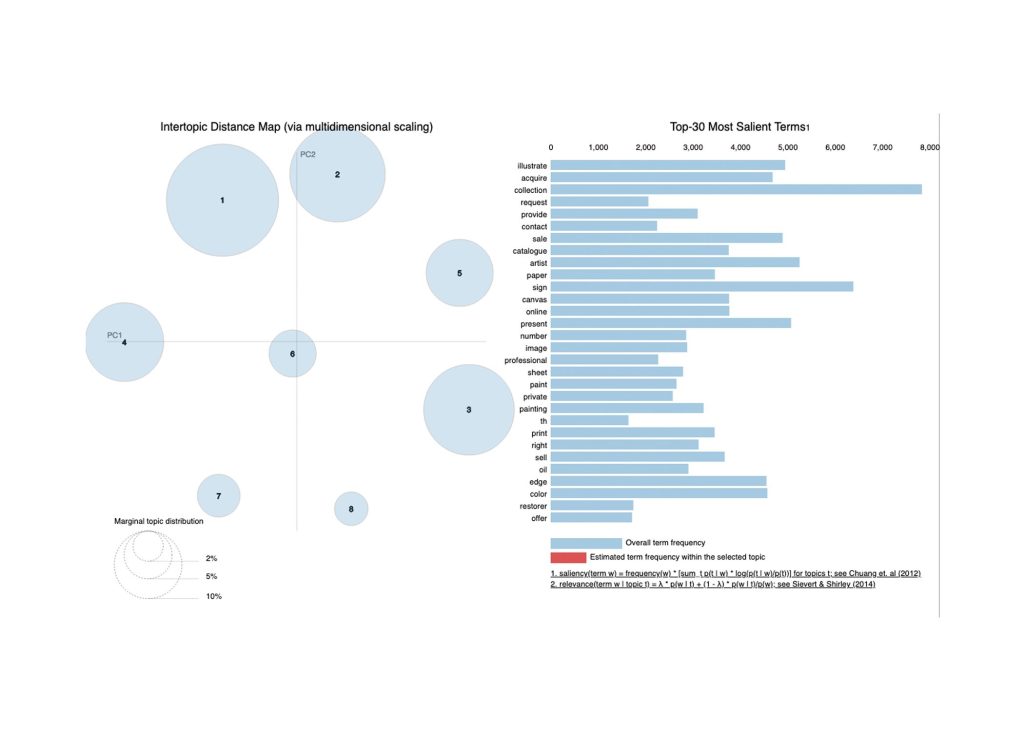
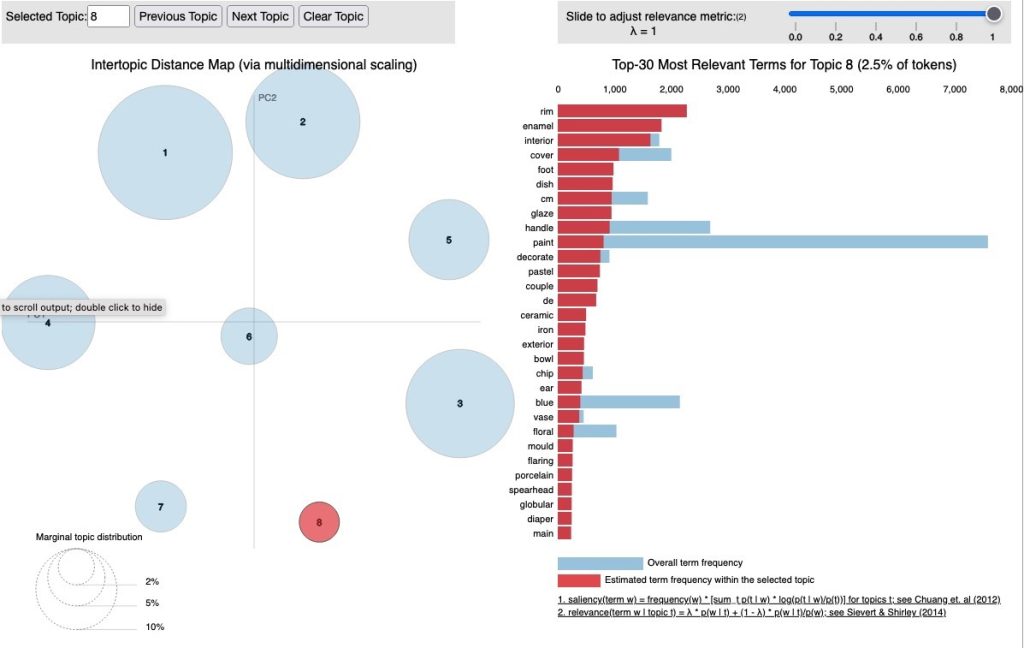
When analyzing the text associated with the topic model, we observed how differently AI interprets aesthetic language. Figure 5 displays the thirty most salient words from the dataset that contributed to the creation of the eight topics. These terms help the model understand aesthetic language and categorize the artworks. Table 3 presents the top three words relevant to each topic. For example, in Topic 8, which includes words used to describe East Asian porcelain pieces (Figure 6), we can see how the relevant terms provide insight into the type of aesthetics represented in that topic. Similar approaches have been used by other researchers exploring aesthetic language used on the Internet.[41] The broader implications of this model for the field of aesthetics are discussed in section 5.

4.2.1. Ethics considerations on the model
Our analysis indicated that our model did not specifically identify any particular type of artist or price range. Future research is needed to explore what patterns may arise from the different topics related to art made by different demographics. The ethical implications here are that if a bad actor were to use topics associated with a more “desirable” aesthetic, they might want to rewrite the descriptions of the artwork. Another important ethical consideration is the demographic makeup of each topic group to ensure that no one group is disproportionately included or excluded by the aesthetic language used. Understanding which economic or demographic groups are associated with each topic cluster would necessitate additional data. The need for more data raises ethical questions about collecting additional data to ensure the current data is free from hidden biases or trends. However, the debate about this question is beyond the scope of this paper.
5. Discussion
In this paper, we present AppraiSet, a dataset of art metadata collected from publicly listed auction lots. This open-source dataset is a first step in developing algorithms, like the one in the case study, that can help a machine form its own aesthetic language.
In the case study, we show how AppraiSet can train a latent dirichlet allocation (LDA) topic model that generates highly coherent topics for grouping and classifying artworks. We show how the model compares to previous research by outperforming on both the coherence and distinctiveness of the topics. Furthermore, we provide examples of topics that include descriptions of print art pieces and sculptures, showing how an AI may develop its own language around certain artworks and styles.
By releasing the dataset and presenting an example use case, we aim to contribute concrete insights to discussions on the intersection of aesthetics and AI. Contemporary aesthetics is at a crossroads. Scholars have found value in applying aesthetic concepts to artworks computationally on a large scale. These deployments identified patterns not previously seen when only working with a handful of pieces at a time. In the age of AI, we must consider how aestheticians will interact with algorithms that develop their own aesthetic principles (section 5.1). Embracing this potential future, we can deliberate on whether AI-developed aesthetic principles should be restricted to AI-generated art (section 5.2).
5.1. The future of computational aesthetics
The field of computational aesthetics is facing a decision point like many other fields with the mass deployment of AI. Traditionally, computational aesthetics has represented the application of aesthetic theories and practices via software to a large-scale collection of art.[42] The software often relied on extracting “hand-crafted” features through computer vision software that analyzed the individual pixel data of a media object.[43] Until now, this has been a heavily human-driven approach, where the software implements measures of aesthetic principles that have been pre-defined by aesthetic scholars.
As larger, higher-quality datasets become available, the capability of algorithms to develop their own language and associations is becoming increasingly commonplace. Studies have already shown that large language models (LLMs) tend to overemphasize certain words or write in unique ways that differ from human language.[44] Therefore, it is not unreasonable to pose the possibility that AI could develop its own aesthetic principles to analyze art. Early evidence of computational aesthetic principles can be seen in Cook and Colton’s work on generating preferences.[45] Combining computational creativity with language models and AppraiSet would give rise to a new iteration of computational aesthetics and significantly impact the academic discipline of aesthetics as a new algorithmic language emerges.
This paper is just an initial case study showing the potential for AI to develop associations trained on just art metadata containing text and integers. Future works can look towards integrating visual data from digital collections for further aesthetic analyses. In light of this potential future, we encourage further discussion into when and how AI-developed aesthetics should be applied. For instance, analyzing art may require art historians and aestheticians to understand AI principles and basic functionality to engage with newly developed AI aesthetics. Similarly, we can imagine how galleries and art institutions may change to reflect tastes defined by algorithmic aesthetic interpretation of art.
5.2. Applying AI aesthetics
The insights gained from historical research on human-developed aesthetics can guide our approach to applying AI aesthetics. Some scholars argue against using Western aesthetic principles in analyzing Eastern art and vice versa.[46] They argue that this can lead to an increased risk of misinterpretation and potential dismissal of culturally salient pieces. In this case, we may advocate that AI aesthetic principles should only evaluate AI-generated art. Not only would this reflect previous scholars’ recommendations, but it would also reflect the growing body of art venues and competitions working to separate AI-generated art from human-made pieces.[47]
Alternatively, some scholars, like Bence Nanay in Contemporary Aesthetics, advocate for examining art through multiple aesthetic principles and lenses in a heavily globalized art world.[48] They argue that this approach offers audiences and artists new modes of exploring, interpreting, and conveying artistic experiences. According to this perspective, algorithmically developed aesthetic principles may serve as a democratizing force, drawing from a global collection of art metadata to offer a more generalized view of aesthetics.
Realistically, the answer likely lies somewhere in between the two positions. Algorithmically developed aesthetics will become just the newest set of principles in the canon of future aesthetics. From this collection of principles, artists and audiences can pick and choose which aesthetic principles interest them and apply them to different interpretations of art. We offer the field of academic aesthetics insights into how these aesthetic positions are formed and open future discussions on how algorithms should be altered to better reflect the needs of aesthetic researchers and students.
6. Conclusion
As AI continues to integrate into the art world, it is poised to reshape our understanding of aesthetics. This paper demonstrates how an algorithm can analyze art metadata to generate topics and concepts related to various artworks. Our research underscores the significance of art data and stresses the need for valuable insights from art experts. As a result, we are making AppraiSet accessible, inviting art scholars to participate in shaping the future of art datasets. Furthermore, we contribute to the discourse on the future of computational aesthetics and the potential role of algorithmically derived aesthetics in evaluating artworks created through human-AI collaboration.
Thomas Şerban von Davie
thomas.von.davier@cs.ox.ac.uk
Thomas Serban von Davier is completing his DPhil in Computer Science from the University of Oxford specializing in artificial intelligence and art. Meanwhile, he is a human-centered AI research scientist at Carnegie Mellon University’s Software Engineering Institute. Thomas has a background as a data engineer, empowering clients with insights into their data and how it can be operationalized for improved model performance and user satisfaction.
Dr. Max Van Kleek
max.van.kleek@cs.ox.ac.uk
Max Van Kleek is Associate Professor of Human-Computer Interaction with the Department of Computer Science at the University of Oxford. He works in the Software Engineering Programme, to deliver course material related to interaction design, the design of secure systems, and usability. He also leads (as co-investigator) the EPSRC PETRAS project: ReTIPS, or Respectful Things in Private Spaces. His current project is designing new Web-architectures to help people re-gain control of information held about them “in the cloud”, from fitness to medical records. He received his PhD from MIT CSAIL in 2011.
Professor Sir Nigel Shadbolt
nigel.shadbolt@cs.ox.ac.uk
Professor Sir Nigel Shadbolt FRS FREng FBCS is Principal of Jesus College and Professorial Research Fellow in Computer Science at the University of Oxford. He is the chairman and co-founder of the Open Data Institute (ODI), based in Shoreditch, London. The ODI specialized in the exploitation of Open Data supporting innovation, training and research in the UK and internationally.
Published July 14, 2025.
Cite this article: Thomas Şerban von Davier, Max Van Kleek, Nigel Shadbolt, “AppraiSet: Discussions on a New Art Dataset,” Contemporary Aesthetics, Special Volume 13 (2025).
Endnotes
![]()
[1] Ziv Epstein, Aaron Hertzmann, the Investigators of Human Creativity, Memo Akten, Hany Farid, Jessica Fjeld, Morgan R. Frank, Matthew Groh, Laura Herman, Neil Leach, Robert Mahari, Alex “Sandy” Pentland, Olga Russakovsky, Hope Schroeder, and Amy Smith, “Art and the Science of Generative AI,” Science, 380(6650):1,110-111, 6 2023.
[2] Cetinic and James She, “Understanding and Creating Art with AI: Review and Outlook,” ACM Trans. Multimedia Computing, Communications, and Applications. 18, 2, Article 66 (May 2022), https://doi.org/10.1145/3475799.
[3] Sergey Karayev, Matthew Trentacoste, Helen Han, Aseem Agarwala, Trevor Darrell, Aaron Hertzmann, and Holger Winnemoeller, “Recognizing Image Style,” technical report, British Machine Vision Conference (BMVC) 2014.
[4] Yihang Bo, Jinhui Yu, and Kang Zhang, “Computational Aesthetics and Applications,” Visual Computing for Industry, Biomedicin, and Art, 1(6), 2018; Florian Hoenig, “Defining Computational Aesthetics,” Computational Aesthetics in Graphics, Visualization and Imaging, L. Neumann, M. Sbert, B. Gooch, and W. Purgathofer (eds), 2005.
[5] Lev Manovich, Instagram and Contemporary Image, 2017, https://manovich.net/index.php/projects/instagram-and-contemporary-image.
[6] Ahmed Elgammal, Bingchen Liu, Mohamed Elhoseiny, and Marian Mazzone, “Can: Creative adversarial networks generating ‘art’ by learning about styles and deviating from style norms,” International Conference on Computational Creativity (ICCC), 2017; Jeff Steward, Harvard Art Museums API, 2015, https://github.com/harvardartmuseums/api-docs.
[7] Blouin, Blouin Art Sales Index, https://www.blouinartsalesindex.com/; Mimi Onuoha, “MimiOnuoha/missing-datasets: An overview and exploration of the concept of missing datasets,” GitHub, https://github.com/MimiOnuoha/missing-datasets; Hans J. Van Miegroet, Kaylee P. Alexander, and Fiene Leunissen, “Imperfect Data, Art Markets and Internet Research,” Arts, 8(3):76, 6 2019.
[8] Ahmed Elgammal, Yan Kang, and Milko Den Leeuw, “Picasso, Matisse, or a Fake? Automated Analysis of Drawings at the Stroke Level for Attribution and Authentication,” Thirty-Second AAAI Conference on Artificial Intelligence. Vol. 32 (1), 2018, https://doi.org/10.1609/aaai.v32i1.11313; Derrall Heath and Dan Ventura, “Creating images by learning image semantics using vector space models,” In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16). AAAI Press, 1202-1208, 2016; Diana S Kim, Ahmed Elgammal, and Marian Mazzone, “Formal Analysis of Art: Proxy learning of visual concepts from style through language models,” AAAI Conference on Artificial Intelligence, 2022.
[9] Sergey Karayev et al., “Recognizing Image Style”; Hui Mao, Ming Cheung, and James She, “DeepArt: Learning Joint Representations of Visual Arts,” In Proceedings of the 25th ACM international conference on Multimedia (MM ’17), Association for Computing Machinery, New York, NY, 1183-1191, 2017, https://doi.org/10.1145/3123266.3123405; Thomas Mensink and Jan Van Gemert, “The Rijksmuseum Challenge: Museum-Centered Visual Recognition,” ICMR’14. 2014; Michael J. Wilber, Chen Fang, Hailin Jin, Aaron Hertzmann, John Collomosse, and Serge Belongie, “BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography,” arxiv. 2017, https://doi.org/10.48550/arXiv.1704.08614; Nikolaos-Antonios Ypsilantis, Noa Garcia, Guangxing Han, Sarah Ibrahimi, Nanne Van Noord, and Giorgos Tolias, “The Met Dataset: Instance-level Recognition for Artworks,” 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks, 2021.
[10] David M. Blei, Andrew Y. Ng, and Michael I. Jordan, “Latent Dirichlet Allocation,” Journal of Machine Learning Research, 3:993-1022, 2003.
[11] L. Hiller and L. Isaacson, “Musical Composition with a High-speed Digital Computer,” Machine Models of Music, 9-21, 1993.
[12] Aline Guillermet, “Vera Molnar’s Computer Paintings,” Representations, 149:1–30, 2 2020.; Vera Molnar, “Toward aesthetic guidelines for paintings with the aid of a computer,” Leonardo, 8:185, 22 1975.; Frieder Nake, “Computer art: Creativity and computability,” Creativity and Cognition 2007, CC2007 – Seeding Creativity: Tools, Media, and Environments, pages 305–306, 2007.; Glenn W. Smith, “An interview with Frieder Nake,” Arts 2019, Vol. 8, Page 69, 8:69, 5 2019.
[13]Adobe, Photoshop generative fill. https://www.adobe.com/uk/products/photoshop/generative-fill.html; MidJourney, https://www.midjourney.com/; Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever, “Zero-Shot Text-to-Image Generation,” Proceedings of the 38th International Conference on Machine Learning, PMLR 139:8821-8831, 2021.
[14] Pat Langley, Herbert A. Simon, Gary Bradshaw, and Jan M. Zytkow, Scientific Discovery: Computational Explorations of the Creative Processes. page 357, 1987.; Marvin Minsky, “Music, Mind, and Meaning,” Computer Music Journal, 5(3):28–44, 1981.; H. A. Simon and R. K. Sumner, “Patterns in music,” Machine Models of Music, pages 83–110, 1968.
[15] Rachel Gordon, “Algorithm finds hidden connections between paintings at the Met,” MIT News. Massachusetts Institute of Technology, 7 2020.; Sotheby’s, “Data Science, Machine Learning and Artificial Intelligence for Art,” Medium, 2018. https://towardsdatascience.com/data-science-machine-learning-and-artificial-intelligence-for-art-1ac48c4fad41.
[16] Ingrid Lunden, “Sotheby’s acquires Thread Genius to Build its Image Recognition and Recommendation Tech,” TechCrunch, 2018. https://techcrunch.com/2018/01/25/sothebys-acquires-thread-genius-to-build-its-image-recognition-and-recommendation-tech/.
[17] Andreas Aakerberg, Kamal Nasrollahi, and Thomas B Moeslund, “RELLISUR: A Real Low-Light Image Super-Resolution Dataset,” 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks, 2021.; Ramya Srinivasan, Emily Denton, Google Research, New York, Jordan Famularo, Negar Rostamzadeh, Fernando Diaz, and Beth Coleman, “Artsheets for Art Datasets,” 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks, 2021.; Nikolaos-Antonios Ypsilantis, Noa Garcia, Guangxing Han, Sarah Ibrahimi, Nanne Van Noord, and Giorgos Tolias, “The Met Dataset: Instance-level Recognition for Artworks,” 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks, 2021.
[18] Blouin, Blouin Art Sales Index. https://www.blouinartsalesindex.com/; artnet, Price Database. https://www.artnet.com/price-database/.
[19] Urbi Garay, “Determinants of art prices and performance by movements: Long-run evidence from an emerging market,” Journal of Business Research, 127:413–426, 4 2021.; Kathryn Graddy and Carl Lieberman, “Death, Bereavement, and Creativity,” Management Science. 2016. https://doi.org/10.1287/mnsc.2017.2850; Hans J. Van Miegroet, Kaylee P. Alexander, and Fiene Leunissen, “Imperfect Data, Art Markets and Internet Research,” Arts, 8(3):76, 6 2019.
[20] Mimi Onuoha, “MimiOnuoha/missing-datasets: An overview and exploration of the concept of missing datasets,” GitHub. https://github.com/MimiOnuoha/missing-datasets; Hans J. Van Miegroet, Kaylee P. Alexander, and Fiene Leunissen, “Imperfect Data, Art Markets and Internet Research,” Arts, 8(3):76, 6 2019.
[21] Jeff Steward, Harvard Art Museums API. https://github.com/harvardartmuseums/api-docs, 2015.
[22] Statista Research Department, “Art Market Worldwide Statistics & Facts,” Statista, 8 2021.
[23] Robert Stecker, “Why Artistic Value is not Aesthetic Value,” In Intersections of Value: Art, Nature, and the Everyday, pages 41–57. Oxford University Press, 3 2019.
[24] Can Ma, Xiaowei Dong, and Junbin Wang, “A Trade-off Between the Artistic Aesthetic Value and Market Value of Paintings With Naive and Childlike Interest Complex,” Empirical Studies of the Arts, 41(2):352–371, 7 2023.
[25] Michael Hutter and Richard Shusterman, “Chapter 6 Value and the Valuation of Art in Economic and Aesthetic Theory,” Handbook of the Economics of Art and Culture, 1:169–208, 1 2006.
[26] Mary Rozell, The Art Collector’s Handbook: A Guide to Collection Management and Care, pages 1–223, Lund Humphries Pub Ltd., 3 2014.
[27] Sotheby’s, “The Value of Art”. https://www.youtube.com/playlist?list=PL9LyZcEeKzXrEh1ff7BELfZ93UsFBgUXJ.
[28] Michael Hutter and Richard Shusterman, “Chapter 6 Value and the Valuation of Art in Economic and Aesthetic Theory,” Handbook of the Economics of Art and Culture, 1:169–208, 1 2006.; Robert Stecker, “Why Artistic Value is not Aesthetic Value,” In Intersections of Value: Art, Nature, and the Everyday, pages 41–57, Oxford University Press, 3 2019.
[29] Mary Rozell, The Art Collector’s Handbook: A Guide to Collection Management and Care, pages 1–223, Lund Humphries Pub Ltd., 3 2014.; Sotheby’s, “The Value of Art”. https://www.youtube.com/playlist?list=PL9LyZcEeKzXrEh1ff7BELfZ93UsFBgUXJ.
[30] Jacques-Emmanuel Galimard, Sylvie Chevret, Emmanuel Curis, and Matthieu Resche-Rigon, “Heckman Imputation Models for Binary or Continuous MNAR outcomes and MAR Predictors,” BMC Medical Research Methodology, 18:90, 2018.; James J. Heckman, “Sample Selection Bias as a Specification Error,” Econometrica, 47(1):153–161, 1979.
[31] Bereket Abera Yilma, Najib Aghenda, Marcelo Romero, Yannick Naudet, and Hervé Panetto, “Personalised Visual art recommendation by learning latent semantic representations,” SMAP 2020 15th International Workshop on Semantic and Social Media Adaptation & Personalization. 2020:1–6, 2020. https://doi.org/10.1109/SMAP49528.2020.9248448; David M Blei, Andrew Y Ng, and Michael I Jordan. “Latent Dirichlet Allocation,” Journal of Machine Learning Research, 3:993–1022, 2003.
[32] Serhad Sarica and Jianxi Luo, “Stopwords in technical language processing,” PLoS ONE, 16(8), 8 2021.
[33] Radim Rehurek and Petr Sojka, “Software Framework for Topic Modelling with Large Corpora,” In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, pages 45–50. ELRA, 5 2010.
[34] Bereket Abera Yilma, Najib Aghenda, Marcelo Romero, Yannick Naudet, Hervé Panetto, “Personalised Visual art recommendation by learning latent semantic representations,” SMAP 2020 15th International Workshop on Semantic and Social Media Adaptation & Personalization. 2020:1–6, 2020. https://doi.org/10.1109/SMAP49528.2020.9248448.
[35] Radim Rehurek and Petr Sojka, “Software Framework for Topic Modelling with Large Corpora,” In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, pages 45–50. ELRA, 5 2010.
[36] Radim Rehurek and Petr Sojka, “Software Framework for Topic Modelling
with Large Corpora,” In Proceedings of the LREC 2010 Workshop on New
Challenges for NLP Frameworks, pages 45–50. ELRA, 5 2010.
[37] Jason Chuang, Christopher D Manning, and Jeffrey Heer, “Visualization techniques for assessing textual topic models,” AVI’12, 2012.; Carson Sievert and Kenneth E Shirley, “pyLDAvis: A method for visualizing and interpreting topics,” Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, pages 63–70, 2014.
[38] Bereket Abera Yilma, Najib Aghenda, Marcelo Romero, Yannick Naudet, Hervé Panetto, “Personalised Visual art recommendation by learning latent semantic representations,” SMAP 2020 15th International Workshop on Semantic and Social Media Adaptation & Personalization. 2020:1–6, 2020. https://doi.org/10.1109/SMAP49528.2020.9248448.
[39] Bereket Abera Yilma, Najib Aghenda, Marcelo Romero, Yannick Naudet, Hervé Panetto, “Personalised Visual art recommendation by learning latent semantic representations,” SMAP 2020 15th International Workshop on Semantic and Social Media Adaptation & Personalization. 2020:1–6, 2020. https://doi.org/10.1109/SMAP49528.2020.9248448.
[40] Bereket Abera Yilma, Najib Aghenda, Marcelo Romero, Yannick Naudet, Hervé Panetto, “Personalised Visual art recommendation by learning latent semantic representations,” SMAP 2020 15th International Workshop on Semantic and Social Media Adaptation & Personalization. 2020:1–6, 2020. https://doi.org/10.1109/SMAP49528.2020.9248448.
[41] Ossi Naukkarinen, “Aesthetics as Space,” Espoo: Aalto ARTS Books, 2020.
[42] Lev Manovich, “Computer vision, human senses, and language of art,” AI and Society, 36(4):1145–1152, 12 2021.
[43] Jiajing Zhang, Yongwei Miao, Junsong Zhang, and Jinhui Yu, “Inkthetics: A Comprehensive Computational Model for Aesthetic Evaluation of Chinese Ink Paintings,” IEEE Access, 8:225857–225871, 2020.
[44] Catherine A. Gao et al., “Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers,” npj Digital Medicine 2023 6:1, 6(1):1–5, 4 2023.; Irene Rae, “The Effects of Perceived AI Use On Content Perceptions,” Proceedings of the CHI Conference on Human Factors in Computing Systems, pages 1–14, 5 2024.
[45] Michael Cook and Simon Colton, “Generating code for expressing simple preferences: Moving on from hardcoding and randomness,” Proceedings of the Sixth International Conference on Computational Creativity, 6 2015.
[46] Kohinoor M. Darda and Emily S. Cross, “The role of expertise and culture in visual art appreciation,” Scientific Reports 2022 12:1, 12(1):1–25, 6 2022.
[47] Alex Greenberger, “Artist Wins Photography Contest After Submitting AI-Generated Image,” ARTnews. Apr. 2023. https://www.artnews.com/art-news/news/ai-generated-image-world-photography-organization-contest-artist-declines-award-1234664549/; Kevin Roose, “AI-Generated Art Won a Prize. Artists Aren’t Happy,” The New York Times, 9 2022. https://www.nytimes.com/2022/09/02/technology/ai-artificial-intelligence-artists.html
[48] Bence Nanay, “Going global: A cautiously optimistic manifesto,” Contemporary Aesthetics, 10, 2022.; Yan Bao, Taoxi Yang, Xiaoxiong Lin, Yuan Fang, Yi Wang, Ernst Pöppel, and Quan Lei, “Aesthetic Preferences for Eastern and Western Traditional Visual Art: Identity Matters,” Frontiers in Psychology, 7(OCT):1596, 10 2016.