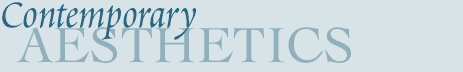
The free access to this article was made possible by support from readers like you. Please consider donating any amount to help defray the cost of our operation.
Data Mining and AI Visualization of Key Terms from U.S. Supreme Court Cases from 1789 to 2022
Eduardo Navas, Luke Meeken, Heidi Biggs, Kory J. Blose, Robbie Fraleigh
Abstract
In this paper, we take on the question of the potential risks of AI in aesthetics: What kind of risks does AI pose? To engage with this question, we focus on how generative AI models’ results consist of decontextualized content that does not always correspond with its historical context. From this standpoint, bias and misinterpretation pose major challenges in academic aesthetics because AI can be used both as a tool to make research more specific and precise and also for quick results that avoid in-depth research and on the surface may appear decisive and accurate. We set out to expose the limitations and misinterpretations of generative models, and to provide ways to critique the models’ shortcomings, using three case studies of specific word searches of Supreme Court cases since its formation in 1789. Each case study includes visualizations based on prompts written by AI models using word results. The results provide a space for critical reflection on the limitations of emerging technologies that make possible new ways to interpret past events based on parameters that are specific to the time of research. The paper concludes with a broader reflection on how academic aesthetics is redefined by generative models, and in turn how academic aesthetics plays a pivotal role in the ongoing development and assessment of artificial intelligence, as AI becomes incorporated into every aspect of cultures and societies.
Key Words
art; aesthetics; artificial intelligence; AI aesthetics; critical theory; cultural analytics; digital humanities; media studies; remix culture; remix theory; remix studies
1. Introduction
In this paper, we take on the question of the potential risks of AI in aesthetics: What kind of risks does AI pose? Our specific focus for this question is on how generative models’ results consist of decontextualized content, meaning that outputs may not always correspond with the context for which they were produced. This is the case in part because—as this paper documents—there is an implicit bias or data noise at play in algorithms. Such bias (noise) results in the recycling of stereotypes made possible because of the content used to train the models, leading to decontextualized material. In terms of research and education, the processes shared below provide ways to engage with the challenges AI poses within the realm of aesthetics, as a specific form of risk that recurringly leans towards misinterpretation by anyone who may not be familiar with the subject matter for which the AI model is used. The risk of misinterpretation makes it more difficult to engage with our historical past, if one is not aware of the limitations of generative AI models.
Bias and misinterpretation are major challenges in the field of academic aesthetics when considering that AI, while it can be used as a tool to make research more specific and precise, can also be used to try to avoid in-depth research for quick results that appear decisive and accurate.[1] In its most direct form, this occurs in the classroom with students using AI tools to complete homework assignments, submitting them as their own work.[2] In aesthetics in academia, AI implementation and usage challenges established assumptions about the relation of labor to aesthetic production. For both academic students and researchers, the need arises to be directly engaged with the subject of research, to be aware of the limitations of AI models and develop the ability to double check findings for accuracy. As a result, this part of research and creativity may increase the labor process to double check AI model results.
This paper exposes the limitations and misinterpretation of generative models, and ways to be critical of the models’ shortcomings, in order to provide fair results with the implementation of smart algorithms. We present results from our experimentation with OpenAI’s GPT models, specifically ChatGPT and DALL-E, for creative projects that are reflective of the limitations inherent in the OpenAI algorithms, that in turn, when not critically engaged with, can mislead people to assume certain conclusions based on AI models output that may appear objective. In terms of aesthetics, this challenges the human interpretation of truth and fairness, in our case for academia but also in culture at large. To reflect on the complexity of this conundrum, we developed our own neural net application that extracts words from datasets that then are used to write sentences to test the way content can be created with smart algorithms. In what follows, we provide three case studies of specific word searches using a dataset that consists of Supreme Court cases since the Court’s formation in 1789.[3] Each case study includes visualizations of the images, following the same basic method of analysis.
The analysis is two-fold in that, first, the results of images based on terms extracted through the implementation of a neural net provide an analogous visual insight into the cultural dynamics at play under which specific words used to extract a series of terms with the neural net in the Supreme Court case decisions throughout their respective historical period. Second, the results provide a space for critical reflection on how emerging technologies offer new ways to interpret past events based on parameters that are specific to the time of research; for our investigation this results in images that do not correspond with historical Supreme Court decisions, even when historical context is explicitly written as part of the prompt. The ethical implications of such decontextualization in a time of ever-increasing speed of information exchange is important to consider, in order to develop methods of fair assessment of information as people become increasingly over-saturated with data.
In this paper, we describe how our neural net app functions and how we used it to produce prompts with ChatGPT. The prompts were then inputted into DALL-E to produce images. We then explain how this process results in decontextualized content that, even when we strived to produce images representative of the prompt statement, did not correspond with the prompt. Given that generative model corporations have not shifted their critical or philosophical approach to AI development, the state of affairs is likely to be of an increased risk of unfair and irresponsible use of current AI technology, even as developers claim that they are working on guardrails to counteract misinformation and misinterpretation.[4]
2. Remix and generative models
The following analysis is contextualized in terms of remix principles, which are useful for critical assessment of generative models results because such models rely on recycling preexisting content in similar ways to remix processes across media prior to the emergence of AI. Our development of a neural net app to analyze word relations from any dataset, described in section 3, consequently is also framed in the context of remix. We provide three case studies, using U.S. Supreme Court decisions with specific examples of visual results for the current Roberts Court. What we emphasize throughout this research is not the technology used for analysis but the conceptual methods and principles behind the implementation of any technology. This is crucial to keep in mind because technological development exponentially is becoming faster, but this means nothing if analysts, researchers, and creative individuals using emerging technology do not have a strong critical foundation motivating their actions. To this effect, remix principles provide a configurable framework for analysis of AI-related content applicable across media (image, music, and text) that can be summarized as follows:
-
Consider the way a cultural object may be created from preexisting sources.
-
Consider different ways in which the object is defined by its parts.
-
Consider different ways parts can be traced to respective sources.
-
Consider how repetition is part of the composition (static or time-based).
-
Consider how the work may be derivative or attain agency as unique (original) based on pattern analysis and on how parts are reconfigured or recombined.
These principles are at the core of our research on neural nets and AI discussed throughout this paper.[5] We can note that the results provided by AI generative engines, as demonstrated in the case studies below, appear generic and neither connote great creativity nor appear to provide an immediately recognizable source based on image results. This largely may be in part because the engines are designed to produce according to self-training data previously produced by humans, meaning that the possibilities for exceptional work, even when it may appear to emerge from time to time, requires a large amount of selective prompting from a human user to achieve a unique result that does not appear generic or derivative. This appears to be the case because the engines lack intentionality, meaning that while they are able to perform selective processes to develop new works, they do not define the motivations or goals behind the task: humans do. It must be made clear here that we are not endorsing the idea of an actual “intelligent” agent, but rather that AI as a tool is often presented as intelligent and it continues to be developed to at least emulate human intelligence. The principles of remix explained in this case are at play in AI in unprecedented ways that do not completely fit previous forms of remix methods, yet the process of production still relies on remix principles to produce AI content. In sum, artificial intelligence is a smart tool that can be seen as a nonhuman, creative actor/agent contributing and shaping cultural production. Our methods are discussed in the following sections and are revisited in our conclusion in section 5. We continue by describing our neural net app in relation to remix principles.
3. Neural net app for semantic analysis of large datasets of text
In this section, we introduce Elephant in the Dark, a web-based tool designed to showcase how the meanings of words can shift depending on the data used to fine-tune AI systems. This tool is part of our broader investigation into how AI reshapes the way we understand and use language, particularly focusing on biases and the potential loss of context in AI-generated content that could lead to what is also known as data noise: meaningless information. Data noise appears in prompt-based text production when a generative model provides inaccurate historical content, and in images when part of the image is distorted, such as missing fingers or distorted eyes or landscapes.
AI models like GPT-4, released on March 13, 2024, are trained on vast amounts of textual data, with GPT-4 itself having been trained on ten trillion words. Models of this size require powerful computer hardware for effective operation. In contrast, smaller models such as Word2Vec, which is trained on the Google News dataset containing about 100 billion words, specialize in capturing semantic relationships among words within that specific corpus and can be operated on a modern laptop. HuggingFace, a community platform for submitted AI models, currently hosts hundreds of user models, many of which rely on word embeddings within their model architecture.[6]
This initial training phase produces what is known as a pretrained model. To enhance its capabilities for specific tasks—such as summarization, question and answer, document classification, and content generation—the model then can undergo a process called fine-tuning. During fine-tuning, the model is adjusted to improve its performance on specific types of data or user-specific data. For example, a model trained on general English might be fine-tuned with a collection of legal documents to better understand and process legal language.
With the increasing popularity and ease-of-use for nontechnical people to engage with and integrate AI-algorithms into their day-to-day creative and professional pursuits, it is increasingly important to highlight the role that underlying training data can have in downstream tasks, especially for application add-ons where the output of one application is the input for the another. In these situations, underlying patterns of bias, stereotyping, or misrepresentation can be augmented.
Elephant in the Dark utilizes Word2Vec, an algorithm that discerns word meanings by examining the contexts in which they appear, similar to how one might learn a language by listening to conversations. This algorithm builds its understanding by observing the words that frequently co-occur. The meanings are then encoded as numerical data, known as embeddings. These embeddings are essential, as they enable the model to comprehend the nuances and relationships among words, shedding light on how language operates across various contexts.
The app compares two texts to extract words related to the word entered on the top right (Figure 1). The neural net was developed as a Streamlit (https://streamlit.io/) application that leverages natural language processing techniques and word embedding models to compute and compare semantic similarity scores between target words and words from two selected textual corpora. In the application, we use Word2Vec (https://arxiv.org/pdf/1301.3781.pdf ) as a language model that learns to represent words as dense vectors in a multidimensional space. These vectors capture semantic relationships between words based on their contexts within the provided text data.
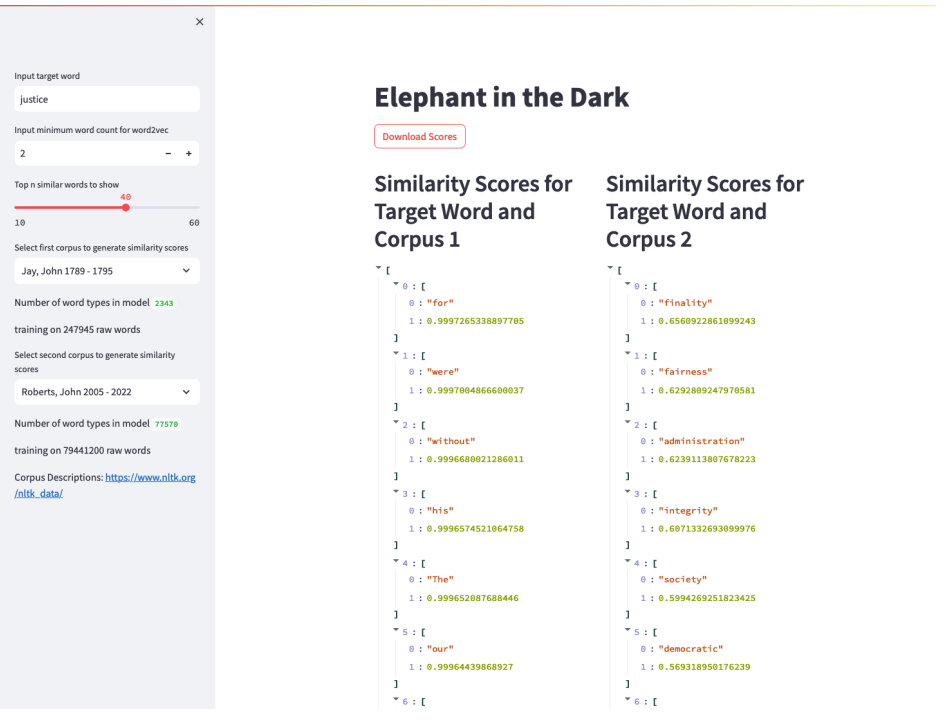
Once the neural net analysis is complete, results are extracted as datasheets (Figure 2). We clean up the data and use word list results to develop sentences using ChatGPT, that in turn are used as prompts with DALL-E. The images produced then can be analyzed for bias and decontextualization.
Our application demonstrates how these adjustments can lead to varied word meanings and associations. Observing these changes is crucial, as it helps us understand how AI models might inherit or amplify biases based on the training data to which they are exposed. This insight is vital for developing AI systems that are both effective and fair, recognizing and mitigating any potential biases that could influence their output.
Remix principles are at play throughout the above-described process at a denotational level. Our app, as explained above, evaluates patterns of repetition to create lists of words that are reused in different U.S. Supreme Court case decisions throughout the text dataset. The neural net app in this case considers how words that are part of a list recur—are remixed or reused in different contexts—throughout the dataset by considering how words are semantically repeated. Our role as researchers is to consider how the list of words (cultural objects) may relate to preexisting sources at a cultural level (as connotation)—that is, according to qualitative assessment. This approach enables us to reflect on the type of cultural environment that should be specific to historical content, as our research demonstrates in the next sections on Supreme Court cases.
It would be unwise to make major claims about specific trends with measured precision, but the list of words, as Figure 2 makes evident, provides a general sense of the types of issues and cultural topics relevant in the United States during a respective Court’s active period. Consider the words listed for the term ‘justice’: finality, fairness, administration, integrity, society, and so on (Figures 1 and 2). The order of the words is important in that the top words have a higher semantic relationship and thus hold greater emphasis throughout the Court’s decisions—meaning that they were of importance in culture at the time. The list in turn was used to produce images with DALL-E, as explained in the next section.
We used our app, Elephant in the Dark, to develop the examples that follow below. More extensive research is available on our R2L resource.[7]
4. Case studies of word queries for AI and remix analysis
The following research was performed between September 2022 and September 2023, before OpenAI released its latest version of DALL-E 3, and later DALL-E 4, where prompts written in ChatGPT can be fed directly to the image AI model.[8] The new feature joining the two AI models does not affect the research described in this section because our goal at this stage was to evaluate the basic process of using sentences produced with ChatGPT as prompts for image production with DALL-E 2. This is also evident when we checked results using ChatGPT-4 and DALL-E 4 to produce more recent images, with similar results to our initial research as explained below in section 5. OpenAI’s new feature of direct submission of content between the two AI models for our earlier analysis functions mainly as a time-saving feature, although as will be evident, also in section 5, OpenAI’s combination of text-to-image option does present stylized image versions that appear homogeneous.
For this study, we mined all Court cases from 1789 to 2022 with our neural network algorithm to attain words that were semantically relevant according to a selected word. We took the top forty words that resulted when searching for a specific term for each of the case studies in all the Court cases since 1789. We chose this range in case we received words that were too general, such as prepositions, articles, or gerunds, and the like, which we omitted. The Courts include Jay, John 1789–1795; Ellsworth, Oliver 1796–1800; Marshal, John, 1801–1835; Taney, Roger, 1836–1864; Chase, Salmon, 1864–1873, Waite, Morrison, 1874–1888; Fuller, Melville, 1888–1910; White, Edward, 1910–1921; Taft, William, 1921–1930; Hughes, Charles, 1930–1941; Stone, Harlan, 1941–1946; Vinson, Fred, 1946–1953; Warren, Earl, 1953–1969; Rehnquist, William, 1986–2005; and Roberts, John, 2005–2022.
There are exceptions of results for some Courts such as Ellsworth, Oliver, 1796–1800 for case study 1 and 3, Jay, John 1789–1795 for case study 2, and Stone, Harlan, 1941–946 for case study 3. The reason for these exceptions is that there was not enough data related to the chosen word in these Court cases for a word list to be created. This is also pointed out in each case study below. For the first case study, we chose the term ‘equality,’ for the second study, we chose ‘water,’ and for the third, we chose ‘Indian.’
We ran queries of twelve Courts against the current Roberts Court. We then took the terms and instructed ChatGPT to produce sentences that were inputted as prompts on DALL-E 2, as explained in each of the three case studies below. Note that there may be slight variation of the way the images were produced, explained at the beginning of each case study. The results are consistent for the evaluation of how decontextualization may be at play when analyzing historical data with use of contemporary data that—as will be explained—is not reflective of the initial historical context when the Court’s decisions were written. As noted previously, in terms of aesthetics (human sense of perception), the point of the analysis is to consider how historical content may be misconfigured when it is conflated with other content that is not part of the historical moment to which the data belongs—this appears quite evident with image production, as will be explained.
Having experimented with OpenAI’s DALL-E 2 system, we found that disconnected strings of words tend to yield images filled with nonsense text whereas grammatical phrases and sentences yield a wider array of imagery. Thus, we used OpenAI’s ChatGPT system to generate sentences with the prompt, “Write a sentence containing the words…,” followed by the ten words generated from each Supreme Court corpus.
We took the top ten results from forty words and instructed ChatGPT to write sentences. The sentences were then inputted on DALL-E 2 to produce images. Any special characters and punctuation marks were omitted if they were part of the top ten results and were replaced with the next top words from the forty words available. It is important to note that DALL-E 2 at times did not allow for some terms to be included because they were considered unacceptable due to potential social harm or inappropriate language. When this happened, the term was replaced with a synonym (terms excluded are mentioned for the respective image results that are available on our full corpus analysis online).[9] We then downloaded the first four images for each set and organized them in grid patterns for comparison. The images produced may appear to some people unappealing or not aesthetically compelling. But we did not instruct DALL-E 2 to rework selected images from initial results because the point of this study is to consider how the AI model evaluates historical data (Court cases) with the contemporary datasets it uses to produce content in general. With DALL-E 2, the first four prompt results provide the broadest possibility for such assessment because once the model is asked to produce more content based on a specific selection from an initial prompt, it tends to enter what is equivalent to an echo-chamber—that is, it tries to streamline or polish an initial rendering. Due to space, we provide one sample of the results for each word case study followed by a general assessment of results.[10] We chose the Roberts Court for an example in each of the case studies because it is the most recent Supreme Court and should offer an immediate sense of the algorithmic limitations at play as they may relate to contemporary times.
4.1. First case study: ‘equality’
The word for the first case study is ‘equality.’ This term was chosen because it remains relevant in current times, given the United States’ history of immigration and slavery.

The top ten terms semantically connected to ‘equality’: neutrality, notions, accountability, dignity, self-government, liberties, freedom, tolerance, democracy, protecting.
Generated sentence: A strong democracy is built upon principles of accountability, protecting individual liberties, and upholding the dignity of all citizens, while fostering self-government and tolerance in a framework of neutrality that respects diverse notions and values of freedom.
Generally, the image sets seem to share a relation with their respective group at the very least, and they appear to be unrelated to the word lists, or the sentences written by ChatGPT. The images also appear unrelated to the time period of the courts, yet each set appears to share a color palette, in addition to misspelled and distorted text. The images do not correspond with the court’s own historical context, and in this sense, we can see how the results are specific to what is available online at the time of research. In other words, it is evident that the generative model is reinterpreting or remixing preexisting content to produce new content. Each court made important decisions regarding equality, particularly in terms of women’s rights, labor laws, slavery, and the recognition of injustices performed against specific groups of people throughout the history of the United States. One thing that can be noted when evaluating the sentences is that there is a tendency in ChatGPT’s algorithm to provide statements that are not critical. This is already a type of censorship based on the concern to produce offensive or insensitive content. The result is images that do not provide specific visual codes that point to a specific time period; and when evaluated without contextual information, none connote specificity to court language, even though the sentences may vaguely allude to some balance of potential conflict related to the word ‘equality.’
In effect, remix is at play in this case by way of what is known as diffusion, which basically means that the generative model evaluates large image sets by separating pixels and adding noise to the pixels to make the source unrecognizable, then to reconstruct them until the result resembles an image similar to one that would fit the prompt.[11] This is a different form of remix based on what will be referred to in other parts of this text as cultural sampling, meaning that the algorithm takes discrete data to analyze quantitatively and then to produce an image that would fit a qualitative recognition of such image by an person passing judgment. Here, we can note how material sampling is at play, meaning the process of direct taking and repositioning pixels to reconfigure them in a completely new form that is no longer a direct copy from the source, as would be the case in music sampling, for example. Instead, the result becomes a new way of performing close emulation, similarly to a music band performing a cover that sounds like the original, but may have some parts changed with no direct taking from the source, thus leaning into cultural citation. This is also similar to what Quentin Tarantino does with close emulation of well-known shots of his favorite films that in turn he reenacts in his own films with different characters and storylines.[12] This development, as the images presented throughout this paper demonstrate, are prone to decontextualization. The nuance of this process becomes evident as we notice the variation of patterns in case studies 2 and 3.
4.2. Case study 2: ‘water’
In this exploration, we chose to evaluate the word ‘water’ to trace the development of environmental sensibilities in the Supreme Court such as the development of the National Environmental Policy Act (NEPA, 1970), the Council on Environmental Quality (CEQ), and, perhaps most well-known, the Environmental Protection Agency (EPA) in the 1970s and beyond. When evaluating all the court results, one can see the shifting “view” of water, from abstract terms to specific activities such as transportation, to infrastructural settings, and eventually related to power and ecological views of nature. In this instance, as in our previous case study, we share only one for a general idea.




Figure 4. Roberts Court 2005–2022
Top ten terms semantically connected to ‘water‘: river, groundwater, flow, surface, stream, waters, oar, electricity, gas, pollutants.
Generated sentence: The river’s flow is supplemented by groundwater, ensuring a steady supply of surface waters for electricity generation, while efforts are made to reduce gas emissions and pollutants to protect the air and the stream’s ecosystem.
In this case study, we can make a more specific claim about our results. Our assessment is that there is a clear kind of “natural” view of water (no boats, no humans) particularly after the Warren Court, which was the court where the EPA was founded and ecological consciousness of the 1970s arose. This is more than evident in the Roberts Court (Figure 4). Before then, water was obviously part of infrastructure and commerce. We can also notice how some terms, such as ‘pipes,’ ‘rivers,’ ‘streams,’ and ‘wildlife’ are key terms that DALL-E 2 uses to produce images. When looking at all of our results, all image sequences include water and natural environments along with major water structures, except for the Ellsworth Court. The reason for this may be that the Court’s word list does not include any words related to water. In that case, the results are generic images of office supplies (not included here).
One thing that can be noted in terms of cultural sampling, as discussed with the first case study, is that once DALL-E 2 chooses a style, in this case photographic, the generative model produces similar images. The same happens with case study 1, where there is text that spells (or rather misspells) ‘democracy.’ We will explain the implications behind this generic tendency across image production after our analysis of case study 3.
4.3. Case study 3: Conceptions and renderings of ‘Indian’ in Supreme Court records
This case study describes the process used to generate expressive images documenting the U.S. Supreme Court’s relationship to the term and concept of ‘Indian’ over the course of the Court’s history. The word ‘Indian’ was chosen because it occurred in the proceedings for all but two of the Supreme Court proceeding corpuses: the Ellsworth Court (1796–1800) and the Stone Court (1941–1946). Initially, we attempted to use more accurate and contemporary terms to track the Supreme Court’s relationship to the ongoing settler-colonial project of the United States. But terms such as ‘Indigenous,’ ‘settler-colonial,’ ‘settler,’ and ‘colonizer’ did not occur in enough corpuses. The presence of the word ‘Indian’ across time may be a consequence of laws written decades or centuries prior still having precedence and still being enforced today—for example 1979’s Indian Child Welfare Act, which in 2023 was ultimately upheld as constitutional in the Haaland v. Brackeen case. As with the other two case studies, we share the Roberts Court results.

Top ten terms semantically connected to ‘Indian”’ Indians, Crow, Narragansett, Creek, native, tribe, tribal, Reservation, Native, ceded.
Generated sentence: The Crow, Narragansett, and Creek tribes were all composed of Native Americans who lived on reservations and maintained their native cultural traditions, even as the government ceded more and more land to non-Native settlers. The tribe’s strong sense of tribal identity helped them to preserve their way of life despite the many challenges they faced.
Several patterns are evident when looking at the semantically linked terms, and the resulting generated images, over the history of the Supreme Court. One clear pattern is that as time progresses, more specific Indigenous communities are named in Supreme Court proceedings. This may reflect the more complex forms the settler-colonial project of the United States has had to engage in over its history, evolving its rhetoric from a general contempt for Indians as an undifferentiated and alien population to increasing negotiations with specific communities asserting their sovereignty and their rights to their land.[13] In this case, when considering the cultural content we can notice how the images are more directly related to Native American themes under the term “Indian.” This may have to do with the availability of images that the generative model can access to develop its own images. When compared with ‘justice’ and ‘water,’ we should consider that the terms are different types of signifiers: ‘justice’ is an abstract term, a hard-to-define concept that cannot be concretely represented with objects, but it can be acknowledged through the relation of objects, whereas ‘water’ is tangible, but also comes in many forms. These terms present real challenges for a generative AI model to produce something that can be contextual. The word ‘Indian’ appears to provide better visual results, but being able to contextualize the accuracy of tribes or other cultural context is essential and ultimately needs to be executed by a person. It is also clear that data noise is at play, as many of the images are slightly distorted. This is also the case with our first case study where all words are misspelled, and our second study where the structures and the water do not come together cleanly. Visual glitches are noticeable at a casual glance across all the images.
5. Limitations of contextual image generation
We could have prompted ChatGPT to write sentences relevant to the Court’s decision, and then write a prompt for DALL-E 2 to produce images that were specific to each Court’s period. To test this, we ran prompts for the John Roberts court, with the corresponding sentences produced by ChatGPT with context including information that the sentence was specific to the Roberts Court. Below are the results for all three terms: ‘equality,’ ‘water,’ and ‘Indian.’


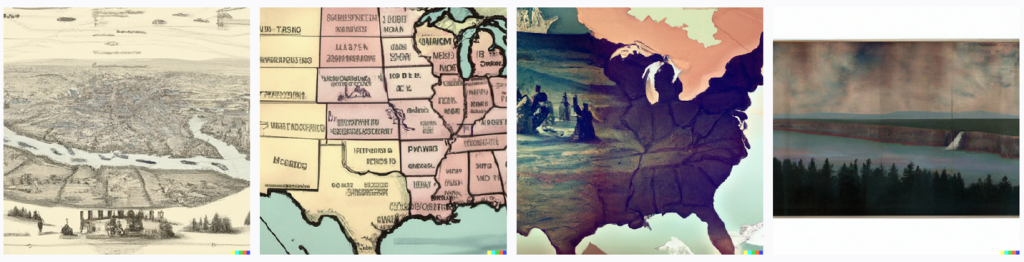
Note that the first set of images emphasizes the concept of courts along with the letters “ro” likely from Roberts; yet, because the word used to gather the list of words was ‘equality,’ the images tend to remain flat, similarly to the results for the same word for all courts. The results for the terms ‘water’ and ‘Indian’ appear better composed. This may be, as previously explained, in part because both words are of objects that can be directly represented in a composite by the AI model. Nevertheless, the results are not so different from the three main case studies because all of the images remain decontextualized without a caption explaining what they are would represent; in these case, the corpus from which the word lists were extracted to produce the sentences that were eventually inputted into DALL-E 2 as prompts.
The point of the research is to consider how two AI models (of image and text) outputted content based on results produced by a neural net app (our own model), without a clear directive from a person in order to assess the algorithm’s ability to produce text and eventually images based on content that comes from a specific time-period. The only thing we have performed is to prompt each AI model to produce results based on data results from our neural net app and its analysis according to the three models’ algorithmic tendencies. Our own prompts are as neutral as possible, to be able to assess how the algorithms use their respective datasets to make sense of the provided word lists. Based on this, we can argue that OpenAI’s models lean towards constant decontextualization, even when specific prompting with historical references is provided, which is the case for our last assessment, above, for which we included details about the Court in the prompt to see if the AI model can provide context-specific-imagery. What we received was generic and unappealing imagery that, without a caption or proper textual description, would not be related to the text data used for its production. We can also conclude that even when trying to attain imagery that may visually represent the context of a court, the results are open for interpretation and need an explanation or caption to be evaluated.
Another argument that can be made is that the generative models will get better at producing images that are fair in terms of their historical context. For this reason, we ran the last three prompts for the Roberts Court in June 2024 and received the following results:












The results of Figures 9, 10, and 11 show improvement in terms of context. The AI results include part of the sentences into the actual design; perhaps this could be considered equivalent to a simulated low-level form of intentionality on the model’s part, as would be performed by an actual person. The result is better contextualized imagery. However, there are other limitations that emerge. For instance, the design style is specific to DALL-E 4 and is becoming recognizable as an AI style no matter what type of image is produced. There are also other limitations previously at play, which are misspelling of words and stereotype renditions particularly for Native Americans. The prompts for ‘equality’ and ‘water’ while stylistically consistent are not so different from the previous results. The takeaway from this updated query of ChatGPT and DALL-E is that humans need to do a lot of editing with multiple prompts, which may get them closer to an idea they may be trying to visualize. However, the implication of these results is that the selective process at play in designing or rendering an image remains just as complex, because generative models are not able to exercise intentionality; at the moment they are only tools. Humans are the ones who need to make the final decisions, based on set goals (intentions) by the prompter.
6. Conclusion
Our focus on generative models exposes the limitations of AI’s reliance on preexisting content to produce material that may appear original to people who may be unaware of the remix principles that have informed cultures across the world since their beginnings. From a broad position, one can claim that AI tools remix human-produced content to produce derivative material that may help streamline simple day-to-day tasks. Ultimately, AI challenges how creativity and aesthetics are defined as a humanistic endeavor because it remixes by combining cultural citation (interpretation of ideas and concepts) and material sampling (direct copying of preexisting recorded content) to produce in terms of cultural sampling (a combination of both).[14] Culture itself thrives on cultural sampling, but the difference with artificial intelligence is that it combines them through quantitative means, whereas humans do it through qualitative means. In other words, humans take copies and ideas and combine them to develop their own creative works in terms of cultural sampling that up until recently was unmeasurable. Artificial intelligence, particularly in the form of generative AI models, is able to evaluate copies of preexisting cultural production—both concrete objects and ideas—to create new content that the models remix through cultural sampling. The result is content that is not directly measurable. This inaccessibility leads to a paradox: the models, even though they quantify data, cannot be evaluated for how they actually perform the task—essentially this is a black box problem of AI.[15] The remix analysis methods and processes discussed in this section provide a way to engage with the emerging need of understanding cultural sampling as performed by AI, as it becomes the cultural variable that defines the ongoing development of AI and likely will be pivotal towards the realization of artificial general intelligence (AGI). Cultural sampling is the key variable in terms of remix that needs to be examined in the process of AI production in aesthetics for academia.
We can now revisit the question, What kind of risks does AI pose? We can state that the greatest risk is and has been that humans face a real challenge to mitigate the misuse of AI given the current incapacities to examine the actual generative process explained in this case as the AI black box problem. Part of this challenge is also the human tendency to take at face value what the engine produces, if the user is mainly interested in quick answers to a complex problem. Academic aesthetics needs to remain critical of not just artificial intelligence but also the ongoing process of emerging technology. In terms of research in education, the goal should remain to implement emerging technology including AI to assess bias and data noise across the media spectrum. This is the real challenge no matter what type of technology emerges in the future. Assessment of remix principles in the process of generative model production provides the means for critical praxis, that is, putting theory into practice.[16]
An issue to note in terms of praxis is that AI has a style, a certain line quality, and a coloring that makes it unique, and this pushes homogeneous forms, which need to be kept in check, as the case studies discussed in this text demonstrate. This can only be done by having an in-depth understanding of form that is not reliant on automation of text or image production. In other words, a need to spend time manually with the basic development of form is still worth investing in even when it may appear to be inefficient when compared to the speed of text, sound, and image production by generative models. This is no different than learning the foundation of mathematics even though we have access to calculators and computers to do accounting and complex equations for humans. The same is the case for all fields in science. If we are not to invest time in researching how things work, we will lose the ability to design and redesign new cultural objects, whether they be analog, digital, material, or immaterial, and new technology will become more derivative with increased homogeneity—thus leading to repetition with decreasing variability. Academia, if it remains true to its mission to search for knowledge, should be able to incorporate AI technology as an efficient tool that can enhance the attainment and dissemination of discoveries and new understanding. The real challenge to this is the growing interest to implement emerging technologies for the exponential growth of corporate wealth. This challenge is not technological, but ideological. Such conundrum has been in place well before the emergence of AI. Artificial intelligence, in effect, is the result of such ideology, which has reshaped aesthetics in academia for many prior generations.
The unprecedented challenge for humans in terms of our sense of perception (aesthetics) beyond academia and within the framework of remix as a cultural practice is to assess how cultural sampling, as analyzed with the three case studies in this occasion, is being reconfigured by generative AI models when they are producing content with quantitative processes that essentially mash cultural citation and material sampling in ways that are moving away from sampling as understood in terms of direct copying and intertextual references. Such shift pushes past reinterpretation of ideas from previous stories (in the case of films, novels, and varying narratives). Cultural sampling can be traced by examining how cultural objects may be created from preexisting sources, both conceptually and materially, and how such sources form the object, and create new meaning, whether it be derivative (mimicry) or autonomous (transformation). The pattern of repetition at play in the analysis included in this paper can also help get a sense of the process behind the creation by considering its evolution over time.
The risk we currently face with emerging technology is that generative models are marketed as ways to expedite the creative process, which some users may understand as taking short cuts, or cutting out the middle person, in this case, the artist, designer, or writer. Given the tendency for decontextualization and misinterpretation that is evident with the case studies above, and the overt need to assess the intention and context of all content, it would be erroneous for anyone to try to consider a generative model equivalent to a hired artist or designer because such model lacks intentionality. And, it is intentionality that matters, which is inherent in having a critical position, even one that ultimately may be mainly the motivation for a bottom line—profits. For this reason, the current models are unable to produce creative works on their own because even if they were able to complete every step in the creative process, they would need to be able to consider the reasons for the object’s initial cultural introduction (intentionality—the reason a human wrote a prompt), and this is only possible according to specific cultural sensibilities that humans share by being part of complex communities. What has happened nevertheless is that generative models are redefining aesthetics in research, academia, and culture at large.
Kory Blose
kjb290@psu.edu
Kory Blose holds a PhD in Data Science and is assistant research professor at Pennsylvania State University. He focuses on research and development using machine learning and statistical modeling methods for supervised and unsupervised learning.
Heidi Bigg
hbiggs7@gatech.edu
Heidi Biggs is an assistant professor at Georgia Institute of Technology in the School of Literature, Media, and Communication’s Digital Media Department. They research human computer interaction (HCI) using humanistic and design-based methods. Their work explores queer and entangled ways of designing for environmental sustainability in computing.
Robbie Fraleigh
rdf5090@psu.edu
Robbie Fraleigh works as a research and development engineer at Pennsylvania State University, where he serves as principal investigator, co-principal investigator, and technical lead on data analytics and data visualization programs. He holds a PhD in experimental physics from Penn State and works at the intersection of data analytics and information design.
Luke Meeken
meekenla@miamioh.edu
Luke Meeken is an assistant professor of art education at Miami University in Oxford Ohio, living and teaching on the traditional homelands of the Myaamia and Shawnee people. His research attends to the cultivation of critical sensitivities to the material qualities of digital and physical places of arts learning. Drawing on critical and performative digital materialisms, and critical and anticolonial readings of place and place-making, his research examines the habits of attention youth bring to the material histories, politics, and embodied interactions of the digital places they participate in and create.
Eduardo Navas
ean13@psu.edu
Eduardo Navas is research professor of art and digital arts & media design and Interim Director of the School of Visual Arts at Pennsylvania State University. He researches and teaches principles of cultural analytics and digital humanities. Navas is the author of several theoretical essays and books on remix studies, art, and media including The Rise of Metacreativity: AI Aesthetics After Remix (Routledge, 2023).
Published July 14, 2025.
Cite this article: Eduardo Navas, Luke Meeken, Heidi Biggs, Kory J. Blose, Robbie Fraleigh, “Data Mining and AI Visualization of Key Terms from U.S. Supreme Court Cases from 1789 to 2022,” Contemporary Aesthetics, Special Volume 13 (2025), accessed date.
Endnotes
![]()
[1] For many limitations of AI and how it has been misconstrued, see Kate Crawford, Atlas of AI (New Haven: Yale University Press, 2021).
[2] Natasha Singer, “Cheating Fears Over Chatbots Were Overblown, New Research Suggests,” New York Times, December 13, 2023, https://www.nytimes.com/2023/12/13/technology/chatbot-cheating-schools-students.html.
[3] The Supreme Court cases can be found at Washington University Law: http://scdb.wustl.edu/.
[4] This has been a major issue in terms of ethics. The New York Times at the time of this writing is suing OpenAI for use of proprietary content and its misuse. See Baker Donelson, “Artificial Intelligence and Copyright Law: The NYT v. OpenAI – Fair Use Implications of Generative AI,” February 2024, https://www.bakerdonelson.com/artificial-intelligence-and-copyright-law-the-nyt-v-openai-fair-use-implications-of-generative-ai.
[5] These principles are discussed in depth in Eduardo Navas, Luke Meeken, Kory J. Blose, Robbie Fraleigh, Alexander Korte, and Eduardo de Moura, “Remix Analytic Methods: A Collaborative Approach to Time-Based Media Media Analysis,” The Routledge Companion to Remix Studies, Second Edition, eds. Eduardo Navas, Owen Gallagher, and xtine burrough (New York, London: Routledge, 2025).
[6] The online platform used for our own app is Huggingface: https://huggingface.co/.
[7] For our ongoing research, see Remix Research Lab, http://navasse.net/r2l.
[8] DALL-E 3 was released during the month of September 2023: https://openai.com/dall-e-3.
[9] For our ongoing research, see Remix Research Lab, http://navasse.net/r2l.
[10] See Remix Research Lab, http://navasse.net/r2l..
[11] Diffusion is a foundational feature for image generative models. DALL-E, Stable Diffusion, and other engines use this process to produce images.
[12] See Everything is a Remix Part 1 for more on Tarantino. Also see, Eduardo Navas, “Sampling Creativity: Material Sampling and Cultural Citation,” Art, Media Design, and Postproduction: Open Guidelines on Appropriation and Remix (New York and London: Routledge, 2018), 31-40.
[13] Newland, B., Tribal sovereignty ruling: Examining Oklahoma v. Castro-Huerta: The implication of the Supreme Court’s ruling on tribal sovereignty, September 20, 2022, https://www.doi.gov/ocl/tribal-sovereignty-ruling.
Anaya, S. J., “The United States Supreme Court and Indigenous peoples: Still a long way to go toward a therapeutic role,” Seattle University Law Review (2000), 24(2), 229-236.
Could you justify to the left on note 13, eliminate the space between 13 and 14, 14 and 15, and make the number 15 of note 15 consistent with the rest?
[14] For more on cultural sampling in relation to artificial intelligence see, Eduardo Navas, Art, Media Design, and Postproduction: Open Guidelines on Appropriation and Remix, Second Edition (New York: Routledge, 2025).
[15] Saurabh Bagchi, “Why We Need to See Inside AI’s Black Box,” Scientific American, May 26, 2023, https://www.scientificamerican.com/article/why-we-need-to-see-inside-ais-black-box/.
[16] Eric Cazdyn, “Enlightenment, Revolution, Cure,” Nothing: Three Inquiries about Buddhism (University of Chicago Press, 2015), 105-184.