The free access to this article was made possible by support from readers like you. Please consider donating any amount to help defray the cost of our operation.
Beauty and the Bit: AI-driven Philosophical Aesthetics
Stefano De Giorgis and Aldo Gangemi
Abstract
This paper presents a novel computational framework for formalizing and analyzing philosophical aesthetics discourse through the integration of knowledge representation techniques and large language models (LLMs). The framework introduces a structure based on four elements combining source texts, core ontology, knowledge graphs, and interpretative mappings to systematically capture both explicit content and implicit semantic relationships in aesthetics texts. Through a case study analyzing works by Dewey, Danto, and Sibley, we demonstrate how this approach enables the systematic reverse engineering of aesthetic analytical methods while maintaining semantic stability and interpretative clarity. The framework leverages human expert annotation alongside LLM capabilities to generate parallel knowledge representations, enabling comparative analysis of different interpretative approaches. Our experimental results reveal complementary strengths between human-annotated and LLM-generated ontologies, suggesting promising directions for hybrid approaches to philosophical knowledge representation. This research contributes to both digital humanities and computational philosophy by demonstrating how modern AI techniques can complement traditional philosophical analysis while addressing core challenges of semantic drift and interpretative bias in aesthetic discourse.
Key Words
aesthetics; AI; AIsthetics; knowledge representation
1. Introduction
The “Perspectival Pluralism Problem”—distinguishing and evaluating alternative theories about similar phenomena—becomes particularly complex in domains where causal explainability is not the primary criterion for theory validation. Philosophical aesthetics exemplifies this challenge, as its discourse encompasses interpretative frameworks that address phenomena ranging from artistic expression to aesthetic experience, where semantic stability and interpretative clarity are paramount concerns. Traditional approaches to aesthetics, and meta-aesthetics—which examines the foundational principles and methodological approaches within aesthetics—have relied on qualitative analysis and expert interpretation, making computational formalization particularly challenging.
Knowledge representation (KR) in computer science encompasses formal methods for encoding human understanding in machine-readable formats, typically through ontologies (formal explicit representation of knowledge in a certain domain), semantic networks, and logical frameworks. Traditional KR approaches focus on capturing explicit, well-defined relationships and hierarchies, often employing description logics or frame-based systems to represent domain knowledge. These methods have proven highly effective in domains with clear taxonomies and logical relationships such as biological classification systems or engineering specifications. However, they face significant challenges when applied to domains characterized by interpretative complexity and semantic ambiguity where relationships between concepts are often implicit, context-dependent, or subject to multiple valid interpretations.
The formalization of knowledge representation in non-STEM (science, technology, engineering, and mathematics) domains presents unique challenges that extend beyond traditional computational approaches. While STEM disciplines primarily rely on causal explanations for theory validation and evolution (modulo the social and political dynamics studied by Fleck,[1] Kuhn,[2] and Feyerabend[3]), the social sciences and humanities (SSH) often deal with phenomena that resist such causal reducibility.
As noted by Jouni-Matti Kuukkanen[4] and Shenghui Wang et al.,[5] phenomena like conceptual drift further complicate the representation of knowledge in these domains, as concepts undergo both extensional and intensional modifications over time.
This paper is the outcome of a hybrid approach and joint work of SSH domain experts, in particular about philosophical aesthetics, and knowledge engineers. It addresses knowledge representation challenges through a novel computational framework for formalizing meta-aesthetic analysis, combining knowledge representation techniques with large language models (LLMs) to capture and compare interpretative frameworks in aesthetics.
By maintaining explicit tracking of rationale, methodological choices, and evaluative criteria, our approach proposes a way to tackle the limits of interpretative horizons while avoiding both naive relativism and oversimplified formalization.[6]
The intersection of computational methods and aesthetics raises fundamental questions about knowledge representation and validation in domains characterized by “floating theory fragments”—theoretical constructs that categorize, explain, or generate empirical phenomena without strict causal foundations. Our framework addresses these challenges through a hybrid approach that combines expert aesthetics’ philosophy annotation, traditional symbolic AI such as knowledge representation, and LLM-based analysis, enabling systematic comparison and validation of different interpretative frameworks while maintaining semantic stability.
This research aims at demonstrating how modern AI techniques can complement traditional philosophical analysis while addressing the core challenges of semantic drift and interpretative bias. By making interpretative frameworks explicit through formal knowledge representation, we provide new tools for understanding and categorizing aesthetics discourse while maintaining the nuanced interpretation characteristic of human expertise.
Our experimental framework adopts a multi-faceted approach to formalize aesthetics discourse through knowledge representation techniques enhanced by LLMs. The methodology centers on the structure ⟨ t,o,kg,im ⟩, where t is a source text (philosophical chapter), o is a predefined core ontology, kg is a generated knowledge graph, and im is a set of interpretative mappings derived from expert annotations on a newly developed ground truth.
The experimental setting includes five main contributions. First, we designed a conceptual model, as shown below in Figure 2, tailored to domain experts’ annotation of philosophical texts for capturing aesthetic concepts and their relationships. This structure is realized adopting an agile methodology in a dialogical setting where knowledge engineers work side by side with domain experts—in this case: aestheticians and philosophy students—to derive some competency questions (CQs), which are then used to develop a conceptual map to guide the experts’ analysis.
Second, domain experts guide the analysis of specific chapters, as detailed in section 3, providing the annotators with the necessary knowledge to build a “ground truth,” namely, a gold standard annotation and interpretation of the text t. After this step, we implement a systematic transformation of expert knowledge from tabular format (.tsv) into a formal RDF knowledge graph, serialized in Turtle syntax, preserving and extending the semantic richness of human interpretation while ensuring computational tractability.
Third, we leverage LLM capabilities to generate an alternative knowledge graph by processing only two of the three components of our experimental pipeline previously listed, namely t—the source text—in conjunction with o—the core ontology—providing a machine-driven perspective on philosophical aesthetics content. This is meant not to replace human analysis but to allow a comparison between a formal representation of the knowledge annotated by the experts and a knowledge base generated by the LLM.
Fourth, we conduct a comparative analysis between the expert-annotated and the LLM-generated knowledge graphs, employing LLM-driven evaluation metrics to assess semantic alignment, conceptual coverage, and interpretative divergence. Because the evaluation environment—namely, the chat interface used—opens new every time, the LLM does not retain any previous information about knowledge extraction and graph generation, therefore allowing an agnostic evaluation performance.
Finally, we exploit generative LLMs’ capacity for bidirectional knowledge transformation by generating “verbalizations”: natural language descriptions of the formal knowledge representation (ontologies and knowledge graphs) complementing the domain experts’ interpretations.
This work aims at showing how to exploit current LLMs technologies to bridge the gap between traditional philosophical analysis and contemporary computational methods.
Given the presence of certain technical terms in the following sections, we provide here a small glossary table with pairs of term-description, to foster a smooth reading of the whole work. This table is not meant as a comprehensive terminological list, nor as a dictionary with exhaustive explanation of the terminology meaning, but as a shortcut to have a quick grasp on certain terms the reader could be less familiar with, and what they mean in this work.
| Term | Description |
| AI – artificial intelligence | Computer systems designed to perform tasks that typically require human intelligence, such as learning, reasoning, and problem-solving. |
| Annotation
validation |
Process of verifying the accuracy and consistency of labels or metadata added to data. |
| Annotator | The person or group of people annotating a certain set of data, usually to validate or build a certain ground truth. |
| Conceptual modeling | Process of creating an abstract representation of a system or domain, focusing on key concepts and their relationships. |
| Domain expert | Professional with deep knowledge in a specific field who helps translate real-world expertise into formal knowledge structures. |
| Fine tuning | Process of adapting a pre-trained AI model to perform specific tasks by training it on a smaller, specialized dataset. |
| Ground truth | Information that is known to be real or true. |
| Internal
representation |
The way information is structured and stored within an AI system’s memory or processing units. |
| Interpretative
mapping |
Process of connecting symbols or concepts from one system to their corresponding meaning in another system. |
| Knowledge
engineering |
Practice of capturing and organizing expert knowledge into formal structures that computers can process. |
| Knowledge graph | Network structure representing real-world entities and their relationships, used to organize and query information. |
| Knowledge
representation |
Methods and formats used to encode information in a way that computers can store, process, and reason about. |
| Large language model | AI system trained on vast amounts of text data to understand and generate human-like language. |
| Ontology | Formal specification of concepts, relationships, and rules within a domain of knowledge. Ontologies including core concepts to a certain domain are called ‘core ontology.’ Ontologies including concepts, relations and rules modeling broad philosophical views, are called ‘foundational ontologies.’ |
| Ontology design
pattern |
Reusable solution template for common problems in ontology development and modeling. |
| Prompt
(nput – output) |
Specific text or data given to an AI system (input) to generate a desired response (output). |
| RDF | Resource description framework: a standard data format for graph-shaped data. |
| Reverse engineering | The process of deriving a conceptual model, and a consequent data schema, from non-structured data, such as free text. |
| SSH | Social sciences and humanities—interdisciplinary fields of study and practice. |
| STEM | Science, technology, engineering, and mathematics—interdisciplinary fields of study and practice. |
| Symbolic AI | AI approach based on explicit symbol manipulation and logical rules rather than statistical learning. |
| Taxonomy | Hierarchical classification system organizing concepts from general to specific. |
| Vectorial space | Mathematical space where data points are represented as vectors, enabling computational analysis. |
| Verbalization | Process of converting formal knowledge representations into natural language expressions. |
| Workflow | Sequence of steps or processes organized to accomplish a specific task or goal. |
2. Related work
Our knowledge representation framework builds upon several established ontological resources and design principles from the semantic web community. Below, we discuss the key ontological foundations that inform our approach.
Following good practices of ontological modeling we: (i) reuse entities from previously existing resources, (ii) align our model to the DOLCE[7] foundational ontology, and (iii) reuse ontology design patterns,[8] as detailed in the following.
2.1. Aesthetics sources
For our analysis, we selected three seminal authors whose work represents distinct approaches to aesthetic inquiry. John Dewey’s pragmatist aesthetics shifts attention from static objects to dynamic experience, arguing that aesthetic experience emerges from the integration of doing and undergoing challenging traditional distinctions between art and ordinary experience. Arthur Danto’s institutional-essentialist theory instead emphasizes how the artworld—the historical and theoretical context surrounding art—transforms ordinary objects into artworks, highlighting the essential role of interpretation and theoretical framing in aesthetic understanding. Finally, Frank Sibley’s work focuses on the relationship between aesthetic and nonaesthetic properties, arguing that aesthetic terms like ‘elegant’ or ‘graceful’ are not condition-governed but require a special kind of perceptual sensitivity that cannot be reduced to rules. So far the work we carried out in the framework of the AIsthetics Project has focused in particular on chapters 3, 4, and 5 of Art as Experience[9]; on chapters 1 and 2 of The Transfiguration of the Commonplace[10]; and on chapters 1, 3, and 5 of Approach to Aesthetics: Collected Papers on Philosophical Aesthetics.[11] These three approaches—institutional-essentialist, perceptual-linguistic, and experiential-pragmatist—provide diverse philosophical material for testing our knowledge representation framework, as they employ different argumentative strategies and conceptual frameworks while addressing fundamental questions in aesthetic theory.
Knowledge representation (KR) is a field of artificial intelligence that focuses on encoding human understanding in machine-processable formats to enable automated reasoning and systematic analysis of complex domains. The formalization of knowledge in computable structures enables automated inference, consistency checking, and the discovery of implicit patterns that might not be immediately apparent through traditional analysis methods. In the KR framework, ontologies provide formal specifications of conceptualizations by defining entity types and their relationships, knowledge graphs (KGs) implement these structures as interconnected networks of information, and knowledge bases combine both terminological schemas and assertional facts to form comprehensive representational
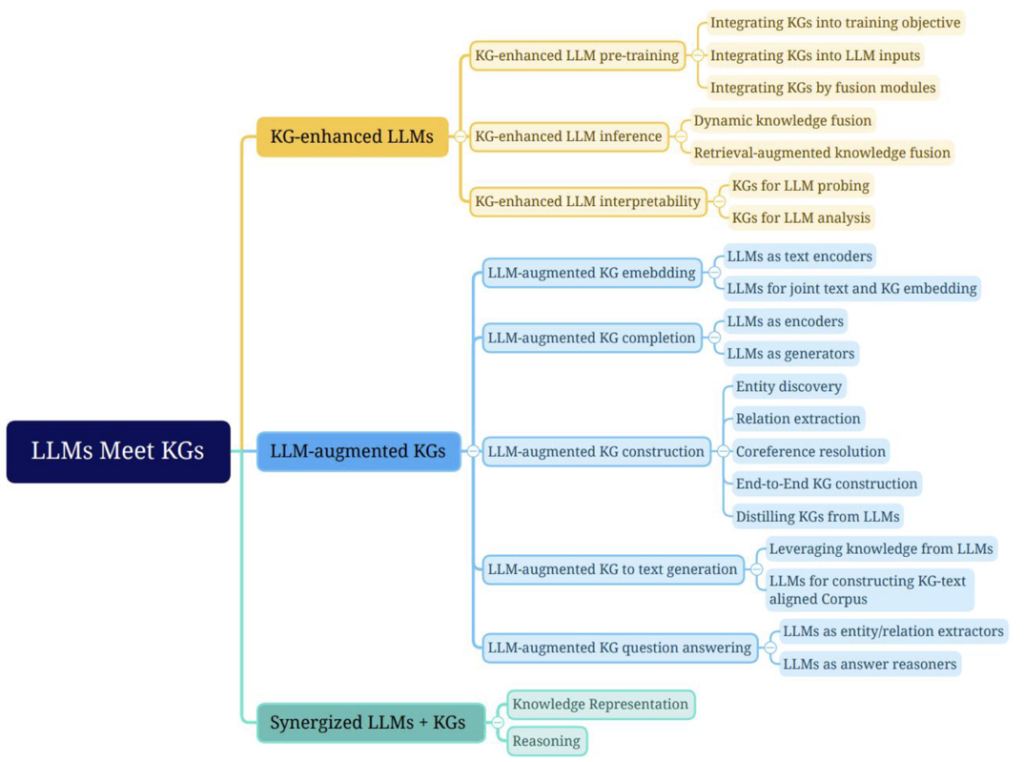
Our work is at the intersection of symbolic and neural techniques, so-called neurosymbolic AI. Regarding joint LLMs and KGs methods, according to Pan et al.,[13] as shown in Figure 1, our approach would be both LLM-augmented KGs and Synergized LLMs + KGs, and in particular LLMs-augmented KGs construction focusing on end-to-end construction and Distilling KGs from LLMs, as well as LLMs-augmented KGs to text generation focusing on Leveraging knowledge from LLMs, and partially LLM augmented KG for question answering adopting LLMs as entity/relations extractors.
Ontology design patterns
Ontology design patterns (ODPs) represent reusable solutions to recurring modeling problems in ontology engineering.[14] These patterns serve as building blocks for constructing domain-specific ontologies while ensuring consistency, modularity, and interoperability. In our work, we leverage ODPs to address common challenges in representing philosophical discourse such as argumentation structures, theoretical frameworks, and conceptual evolution. The pattern-based approach enables us to maintain consistency across different modules of our knowledge representation framework while allowing for the flexibility needed to capture the nuances of different approaches in philosophical aesthetics. Ontology design patterns particularly inform our core ontology design, helping us balance expressiveness with maintainability and ensuring our model can accommodate various philosophical perspectives and analytical approaches.
The reused pattern here is information realization,[15] which allows to formally represent the relation between an abstract piece of information and its physical realization.
Ontologies for textual documents
FaBiO[16] extends the FRBR (functional requirements for bBibliographic records)[17] conceptual model to provide a comprehensive framework for describing bibliographic entities. This ontology is particularly relevant to our work as it enables precise representation of published philosophical works and their various expressions. FaBiO’s sophisticated model for capturing the relationships between works, expressions, manifestations, and items allows us to accurately represent the complex network of citations, references, and intellectual lineage in academic aesthetics discourse. The ontology’s capability to describe both published and potentially publishable entities aligns well with our need to represent various forms of aesthetics texts, from formal publications to manuscript drafts and lecture notes.
The document components ontology (DoCo)[18] offers a structured vocabulary for representing both the structural and rhetorical elements of documents. In our context, DoCO provides essential concepts for decomposing philosophical texts into meaningful units of analysis. The ontology’s distinction between structural components (such as sections, paragraphs, and chapters) and rhetorical elements (like introductions, discussions, and arguments) is particularly valuable for our analysis of philosophical aesthetics texts. We reuse some of the DoCO and FaBiO classes to align some of our entities referring to ‘Chapter,’ ‘Author,’ and so on.
DOLCE foundational ontology: Descriptive ontology for linguistic and cognitive engineering
DOLCE[19] serves as a foundational ontology that provides rigorous philosophical grounding for our knowledge representation framework. As a top-level ontology, DOLCE offers a sophisticated taxonomy of abstract concepts and relationships that helps bridge the gap between natural language expressions and formal representations. Its commitment to cognitive semantics and linguistic structures makes it particularly suitable for representing philosophical discourse.
Details about the specific alignments and classes reuse are given in the next section, as well as provided directly in the ontology files, namely the .ttl files in the dedicated GitHub repository.
3. Methodology
Our research relies on a systematic approach to unpacking the semantics of interpretative frameworks in philosophical aesthetics. To do so, we introduce a recently developed hypothesis to ground aesthetics on a tripartite classification system theorized originally by Iannilli and Naukkarinen in the context of the AIsthetics Project: action- or verb-oriented, object- or noun-oriented, and adjective- or property-oriented analysis. For an extensive description of this tripartite classification, refer to Iannilli and Naukkarinen’s contribution, “Human and AI Perspectives on Academic Aesthetics,” included in this same volume.
This approach has been reworked here in a functional perspective adopting computational knowledge representation techniques.
3.1. Formal framework and workflow
Our workflow is grounded formally on four elements
⟨ t,o,kg,im ⟩
where each component plays a specific role in the knowledge representation process:
- t (text): is the source philosophical text under analysis. In our framework, these are carefully selected excerpts from seminal works in philosophical aesthetics that exemplify different analytical approaches and theoretical frameworks. The textual component serves as the primary input for both human annotators and LLM-based analysis to produce the ground truth.
- o (ontology): denotes the core ontology (see the conceptual schema of core ontology in Figure 2, below) that provides the fundamental conceptual structure for analysis. This ontology encapsulates the key concepts, relationships, and axioms necessary for representing academic aesthetics discourse. It serves as a semantic backbone that guides both human annotation and automated analysis, ensuring consistency in knowledge representation across different texts and annotators.
- kg (knowledge graph): represents the formal graph structure generated through the analysis process. These graphs capture the semantic relationships, argumentative structures, and conceptual frameworks present in the source texts. Multiple knowledge graphs may be generated from different sections of the same text or from different annotators, eventually harmonized into a unique comprehensive representation.
- im (interpretative mapping): encompasses the structured human annotations produced by domain experts and trained annotators. These mappings, initially captured in tabular format, represent the human interpretation of how the source text aligns with the conceptual framework defined in the core ontology. The interpretative map pings serve as a crucial bridge between the natural language of philosophical texts and their formal representation in the knowledge graph.
This four-elements structure provides a systematic framework to formalize explicit content and implicit semantic relationships in aesthetics texts, and a versatile structure for our experimental setting. Furthermore, it allows us to maintain traceability between source material, formal representations, and expert interpretations. The framework’s modularity allows for iterative refinement of each component while maintaining semantic consistency across the entire analysis process.
Our approach combines traditional knowledge engineering practices with LLMs’ capabilities. Several interconnected phases comprise the methodology, each building upon the previous one. We now proceed to list the various steps of our approach, which are then exemplified by one use case in section 4.
Knowledge engineering and conceptual modeling
The first step involves collaborative work between domain experts, namely knowledge engineers and aestheticians to establish a conceptual schema. This schema serves as a formal backbone for analyzing philosophical aesthetics texts, ensuring consistency and reproducibility in the annotation process. The resulting conceptual model is then formalized into a core ontology, which provides the foundational semantic structure for subsequent knowledge representation tasks.
Expert-driven annotation process
In this second step, domain experts train annotators to analyze selected texts in aesthetics, focusing on works by Dewey, Danto, and Sibley. These authors were selected for their diverse analytical approaches. Annotators employ a structured template (table with slots to be filled in) derived from the conceptual model, to capture and reverse engineer the aesthetic critical thought patterns present in the texts. This process results in tabular data that explicitly maps the authors’ philosophical frameworks to our conceptual schema. We employ a tabular template as a compromise between the freedom of more traditional qualitative written analysis in natural language, and the need to keep the analysis and information computationally tractable in some way. Leaving the freedom to list relevant concepts and elements, and to add gloss in natural language and elaborate on necessary schematization, allows to keep human-like explainability while encapsulating the information in a fixed, shared, and easy-to-formally-transpose tabular structure.
Knowledge graph construction and integration
After the annotation, the produced data undergoes a transformation process where tabular annotations are converted into RDF-based domain modules that incorporate the core ontology’s semantic structure. This transformation can be followed by an integration phase where multiple graphs derived from different sections of the same source material (for example, different chapters of the same book) are combined. The process culminates in the generation of comprehensive knowledge graphs that encompass multiple topics and sources, with careful attention paid to harmonizing semantic relationships across different textual sources. The harmonizing is LLM-based, giving as input the knowledge graphs generated from different textual chunks, therefore including both new data as detailed in the following textual factoids, namely portions of text including a certain relevant concept, and new concepts. The division in chapters, in fact, usually correlates with the separation of topics, and having a knowledge graph per each chapter allows to have a formalization of the thought of a certain author on a specific topic while having a harmonization of all the graphs allows to have a wrap up of the whole theoretical proposal.
For the harmonization, analysis, and module generation presented in the following paragraphs, we opted for a specific LLM: Claude 3.5 Sonnet. We opted for this choice instead of, for example, ChatGPT, Mistral, Llama, or the like because of Claude’s better performance obtained in the hands-on knowledge engineer’s experimentation. From here on, when we refer to LLM-based processes, analysis, generation, and so on, the LLM used in this run of experiments is Claude 3.5 Sonnet, but being a general framework, it can be replicated with any desired LLM.
LLM-based experimental validation
Our experimental phase leverages large language models to generate parallel domain-specific modules using only the source texts and core ontology as input. This means that, considering the componency of our approach ⟨ t,o,kg,im ⟩, while the proper generation of kg depends on t (the original chapter text), o (the core ontology adopted as driving conceptual structure for the analysis), and im (the expert annotator analysis), the LLM-driven generation is instead lacking im and generates kg solely from t and o.
These LLM-generated modules are then re-injected together with human-driven ones to an LLM, to obtain an approximation of semantic alignment and interpretative accuracy. Although we cannot state that the LLM is qualified to evaluate the correctness of both human-based or LLM-based annotation, what we know it is able to perform in a form of similarity measurement, namely stating what are the overlaps between the two models, what is the granularity of details, and some quantitative analysis such as the number of concepts and relevant textual chunks retrieved, the density of relations among them, and so on. Future works include ground truth validation with domain experts, as described in section 5.
Analysis and pattern discovery
In summary, the resulting formal structure enables systematic reverse engineering of aesthetic analytical approaches from any author within the domain. Through this framework, we can identify latent semantic relations across different philosophical frameworks and discover overlapping approaches in aesthetics analysis. The methodology could be used to make emerge similar methodological patterns across different authors and schools of thought while maintaining the flexibility to accommodate new sources and interpretative frameworks. This systematic approach to pattern discovery provides valuable insights into the underlying structures of aesthetics discourse. It furthermore is a first step towards applying a flexible approach grounded in intensional mereology, namely the formal analysis of conceptual componency, and their network of relations, to a field that usually escapes rigid formalization.
Finally, this methodology provides a scalable framework for formalizing philosophical aesthetics analysis while maintaining the flexibility to accommodate new sources, perspectives, and interpretative frameworks. The iterative nature of the process allows for continuous refinement of the conceptual model based on emerging patterns and insights from domain experts.
3.2. Conceptual schema and core ontology
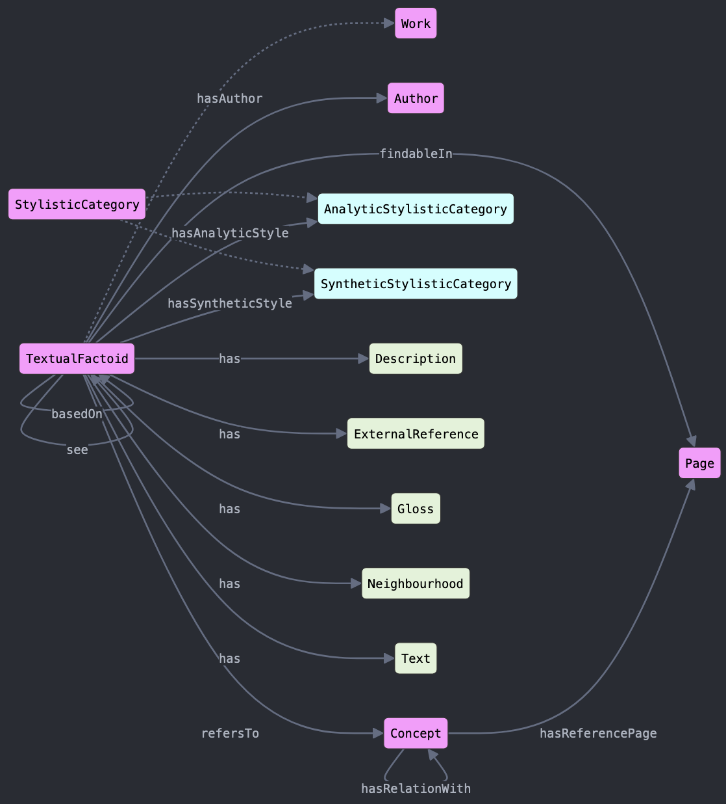
The conceptual schema developed with the domain experts, and adopted by the annotations to generate data, is the backbone for the core ontology module. Figure 2, above, shows a visualization of this core ontology structure. We provide here a list of core elements of our conceptual model that can be used for analyzing philosophical texts:
- Identifier (ID): A reference pointer to a conceptual factoid—a text segment that introduces, mentions, or describes a concept in a particular style; enables both quantitative analysis (concept frequency) and qualitative analysis (stylistic patterns).
- Authorship: The attribution of the text segment’s creator.
- Location: A page reference for text segment traceability.
- Text Content: The relevant textual excerpt containing the conceptual content.
- Primary concept (concept #1): The core concept either directly stated or implied within the text segment.
- Conceptual relations:
* The relationship type with secondary concepts (concept #2).
* Secondary concept identification.
* The relationship context (“concept neighborhood”) capturing broader aesthetic considerations for n-ary relations.
- Expert annotation: A domain expert’s analysis of the text segment’s relevance and significance.
- Stylistic classification:
* Analytical categories: descriptive, honorific, metaphoric, evocative, visual, dialectic, Thesis, progressive-linear, paratactic
* Synthetic categories: verbal, nominal, adjectival
- Aesthetic commentary: The author’s explicit reflections or corollaries related to their aesthetic perspective.
This model enables systematic analysis of both conceptual content and stylistic presentation in aesthetic (but potentially any) philosophical texts, recognizing their inherent interconnection in philosophical discourse.
4. Experiments
To show how our methodology can be applied and what are the results that can be produced, we illustrate here one example of pipeline application from analysis to models comparison and verbalization. Let’s consider Danto’s Chapter 1 from The Transfiguration of the Commonplace.
We start from a table with the following headers:
ID/textual factoid, author, page, piece of text, concept, reference page, relation to concept #2, concept #2, concept neighborhood (aesthetic aspect), gloss, analytic stylistic category, synthetic stylistic category, major stylistic category, minor stylistic category, aesthetic corollary.
Each of these elements can be mapped to one of the categories described above in section 3.
4.1. Structural comparison
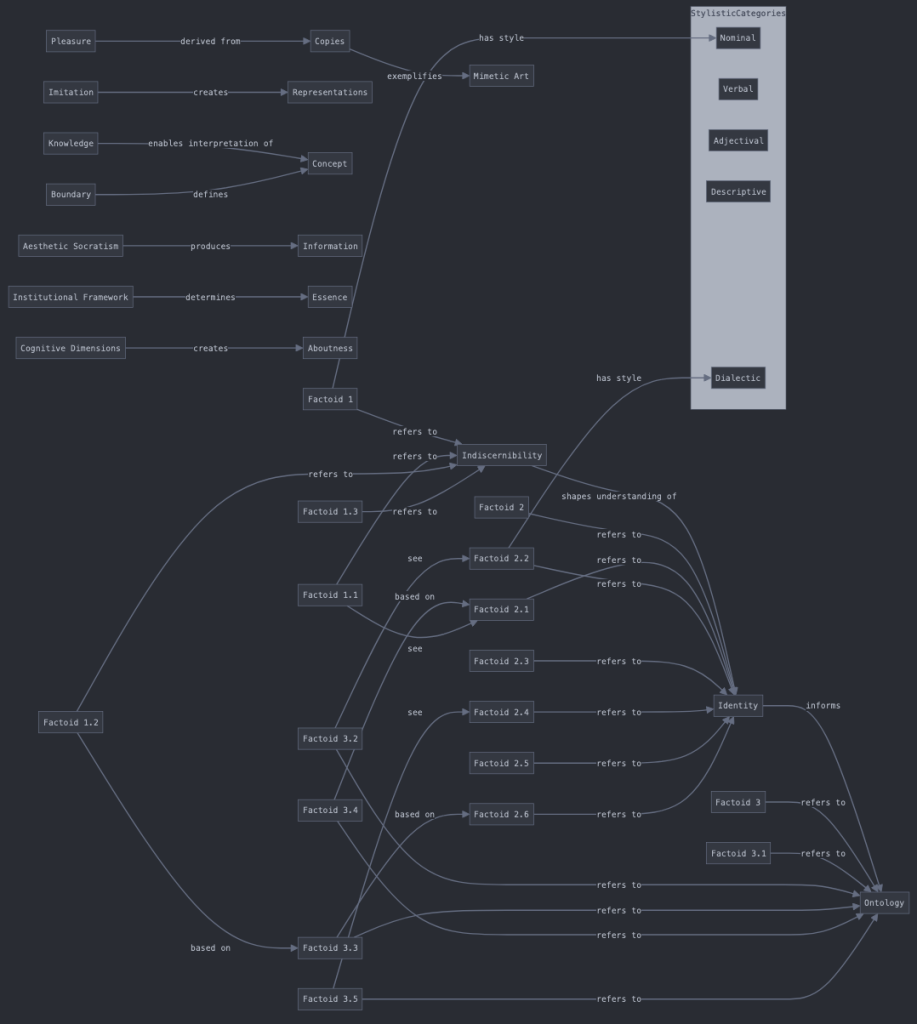
Examining the human-annotated ontology (danto-ch1.ttl) and the large language model (LLM)-generated ontology (danto-ch1-claude.ttl) reveals several notable structural differences in their organization and emphasis. The human-annotated version emphasizes a textual analysis framework, incorporating extensive properties for managing relationships between textual elements. This is evident in its sophisticated system of properties like basedOn, see, and hasNeighbourhood, which create a rich network of textual connections. In contrast, the LLM-generated version places greater emphasis on conceptual hierarchies related to the philosophy of art, introducing specific class structures for artistic and ontological statuses. The class hierarchy between the two versions reflects this fundamental difference in approach. Where the human version prioritizes textual analysis through classes like textual factoid and the dual categories of analytic and synthetic stylistic category, the LLM version constructs a framework more directly focused on art-theoretical concepts through classes like ArtObject, ArtisticStatus, and OntologicalStatus.
4.2. Conceptual overlap and coherence
Despite their structural differences, the ontologies display significant conceptual overlap in their treatment of Danto’s core ideas. Both capture the central concept of indiscernibility, though they approach it differently. The LLM version’s explicit representation of the IndiscernibilityProblem aligns remarkably well with the human version’s treatment of indiscernibility as a fundamental concept. Similarly, both ontologies incorporate the notion of artistic conventions and institutional frameworks, though they structure these relationships differently.
The distinction between mere real things and artworks, crucial to Danto’s philosophy, is preserved in both ontologies, though expressed through different mechanisms. The LLM version makes this distinction explicit through its class hierarchy while the human version embeds it within its textual analysis framework.
4.3. Analysis verbalization
Thanks to language generation capabilities, we can exploit LLMs’ descriptive abilities to have a verbalization, namely an explanation in natural language of a certain piece of information, expressed, for example, as in our case, as a knowledge graph.
When prompted from the chat interface, asked to verbalize, for example, the core ontology providing a brief description of usage, Claude 3.5 Sonnet provides this explanation:

While, when given as input, Danto’s Chapter 1 knowledge graph generated from human annotation vs. Danto’s Chapter 1 generated without human annotation, prompted on the differences between the graphs, it generates:

4.4. Critical analysis and integration possibilities
The comparison reveals that these ontologies might better be viewed as complementary rather than competing approaches. The human version’s excellence in textual analysis and scholarly annotation complements the LLM version’s clearer philosophical framework and concrete examples. Together, they offer a more complete picture of both the text, its concepts, the examples used to describe a certain conceptual framework, and, indirectly, the writing style.
The LLM-generated ontology shows remarkable conceptual coherence with the human-annotated version in its treatment of Danto’s core philosophical concerns. It correctly identifies key theoretical relationships and preserves essential distinctions, suggesting that LLMs effectively can extract and represent philosophical concepts and relationships. However, the human annotation process remains crucial for sophisticated textual analysis and expert interpretation.
This analysis suggests promising directions for future integration. The textual analysis framework from the human version could be merged with the philosophical hierarchy of the LLM version, creating a unified ontology that preserves both textual analysis capabilities and philosophical clarity. The LLM’s approach to concrete examples could be maintained while incorporating the human version’s analytical depth. Such integration would leverage the strengths of both approaches while compensating for their respective limitations.
The successful aspects of the LLM-generated ontology indicate that artificial intelligence can meaningfully contribute to philosophical knowledge representation, particularly in identifying and structuring core concepts. However, the unique strengths of human annotation, especially in nuanced textual analysis and scholarly interpretation, suggest that optimal results can be achieved only through a hybrid approach combining machine and human expertise. A promising research direction[20] is the addition of heuristical conditioning in the automated process, which can instruct LLMs to (partly) extract the kind of implicit knowledge that humans have competence upon. Heuristics could be given to the model jointly with the other elements described here, especially when they have been defined from established interpretation practices in aesthetics.
5. Discussion and remarks
One crucial direction for future work involves the validation of our ontological framework by domain experts in academic aesthetics. While our current approach demonstrates promising results in representing philosophical concepts and relationships, systematic evaluation by scholars in aesthetics—namely, data validation by humans directly instructed by domain experts—would provide valuable insights into the accuracy and completeness of our knowledge representation. Such validation could involve structured interviews with experts, comparative analysis of our ontological modules against established philosophical frameworks, and potential refinements based on expert feedback. This process would not only validate our current work but also guide the development of future ontological modules.
The current implementation relies on Claude 3.5 Sonnet for natural language processing and knowledge extraction. Future work should evaluate the performance of other large language models (LLMs) to assess the generalizability of our approach. Different LLMs might exhibit varying capabilities in understanding and representing complex philosophical concepts, and a comparative analysis could reveal which models are best suited for different aspects of aesthetic knowledge representation. This cross-model validation would also help identify whether certain philosophical insights are model-dependent or consistently captured across different architectures.
Our study focused on the works of Dewey, Danto, and Sibley, but expanding the scope to include other influential aestheticians will provide a more comprehensive understanding of how our framework handles diverse philosophical perspectives. Testing with additional authors such as Goodman, Beardsley, or contemporary aestheticians will help validate the flexibility and robustness of our ontological approach. This expansion will also facilitate the identification of common patterns and divergences in aesthetic thought across different philosophical traditions.
Regarding textual analysis, future work should explore the processing of full texts rather than selected chapters. This would involve developing more sophisticated methods for maintaining conceptual consistency across larger bodies of work, also due to the LLMs’ problem of hallucinations, that is, generation of invented, unreliable textual material. One promising approach would be to implement structured prompting techniques that systematically harmonize ontological representations across different chapters while preserving the nuanced development of ideas throughout an author’s complete work. This would help address potential issues of contextual coherence and conceptual evolution within longer texts.
The implementation of retrieval-augmented generation (RAG) represents another promising direction. This approach would enable more precise and contextually relevant aesthetic analysis by allowing the system to retrieve specific insights from an author’s work when analyzing new aesthetic concepts or cases. Retrieval-augmented generation could enhance the system’s ability to maintain fidelity to an author’s original thoughts while applying their theoretical framework to novel situations. This would be particularly valuable for educational applications and comparative aesthetic analysis.
Finally, knowledge-augmented generation (KAG) offers exciting possibilities for extending the analytical capabilities of our framework. By leveraging our core ontology and conceptual model, KAG can enable the system to perform synthetic analyses of aesthetic topics not explicitly addressed by the original authors. This approach would simulate how these philosophers may have analyzed contemporary art forms or aesthetic phenomena, guided by the formal representation of their theoretical frameworks. While such synthetic analyses would require careful validation, they could provide valuable insights into the applicability of historical aesthetic theories to contemporary contexts.
6. Conclusions and future works
This paper has presented a novel framework for formalizing and analyzing philosophical aesthetics discourse through the integration of knowledge representation techniques and large language models (LLMs). Our approach, built on a quadruple structure ⟨ t,o,kg,im ⟩, demonstrates how computational methods can complement traditional philosophical analysis while preserving the nuanced interpretation characteristic of human expertise.
The key contributions of our work include:
-
A systematic methodology for reverse engineering aesthetics frameworks through formal knowledge representation, combining expert annotation with LLM-based analysis.
-
A flexible core ontology that successfully captures the complexities of aesthetic discourse while maintaining semantic stability and interpretative clarity.
-
A comparative framework that enables systematic analysis of different philosophical approaches to aesthetics, as demonstrated through our analysis of works by Dewey, Danto, and Sibley.
-
An innovative approach to knowledge graph generation and validation that leverages both human expertise and LLM capabilities, showing how AI can contribute meaningfully to philosophical analysis while acknowledging its limitations.
Our experiments reveal that LLMs can effectively extract and represent core philosophical concepts and relationships, though they may not match the sophistication of human analysis in capturing nuanced textual relationships and scholarly interpretations. This suggests that optimal results in philosophical knowledge representation can be achieved through a hybrid approach that combines machine efficiency with human expertise.
The framework’s ability to maintain explicit tracking of rationale, methodological choices, and evaluative criteria addresses fundamental challenges in formalizing interpretative domains while avoiding both naive relativism and oversimplified formalization. By making interpretative frameworks explicit through formal knowledge representation, we provide new tools for understanding and categorizing academic aesthetics discourse.
The methodology developed here has potential implications beyond aesthetics. Our approach to handling “floating theory fragments” could be adapted to other domains in the humanities and social sciences where interpretative complexity and semantic ambiguity are central concerns.
Looking forward, several promising directions emerge for future research:
-
The expansion of the ontological framework to encompass a broader range of philosophical aesthetics traditions and contemporary approaches.
-
The development of more sophisticated methods for harmonizing knowledge graphs across larger bodies of philosophical work.
-
The integration of additional LLM capabilities, particularly in areas of semantic analysis and natural language generation.
-
An exploration of applications in educational contexts, where formal representation of philosophical frameworks may enhance teaching and learning of aesthetic theory.
-
An investigation of how this framework can contribute to ongoing discussions about the role of AI in philosophical inquiry and interpretation.
In conclusion, this work paves the way to potential meaningful integration of computational methods and philosophical analysis, merging human expertise in interpretative tasks and leaving the “heavy lifting” of data generation to artificial intelligence systems.
Stefano De Giorgis
stefano.degiorgis@cnr.it
Stefano De Giorgis is a post-doctoral researcher at the Institute for Sciences and Technologies – National Research Council. His research focuses on cognitive computing, knowledge representation, and digital humanities. His focus is on realizing grounded world models with hybrid neuro-symbolic approaches.
Aldo Gangemi
aldo.gangemi@unibo.it
Aldo Gangemi is full professor at the Philosophy Department, University of Bologna. He is former director of the Institute for Cognitive Sciences and Technologies – National Research Council. His research interests span from traditional knowledge representation, to pioneering artificial intelligence, in particular hybrid neuro-symbolic systems, with a focus on semantics, knowledge engineering, and tacit knowledge elicitation.
Published on July 14, 2025.
Cite this article, Stefano De Giorgis & Aldo Gangemi, “Beauty and the Bit: AI-driven Philosophical Aesthetics,” Contemporary Aesthetics, Special Volume 13 (2025), accessed date.
Acknowledgements
This work was supported by the Future Artificial Intelligence Research (FAIR) project, code PE00000013 CUP 53C22003630006.
Appendix
Additional material can be found on the dedicated GitHub: https://anonymous.4open.science/r/AIsthetics-62D7/README.md.
Here we provide useful information to read and interpret files. All the files are named following this convention:
author name.chapter.file extension
where:
- author name is usually “dewey,” “danto,” or “sibley”;
- name chapter is simplified as “ch-chapter number”;
- file extension: indicates the type of file, and therefore the type of content:
* .ttl : are the knowledge graphs generated for each chapter, or textual chunk.
* .mmd : the visualization in mermaid code.
* .png : the visualization of the knowledge graphs as images.
* .prompt : the prompt used to generate the knowledge graphs related to a certain chapter.
Endnotes
![]()
[1] Ludwik Fleck, Entstehung und Entwicklung einer wissenschaftlichen Tatsache: Einführung in die Lehre vom Denkstil und Denkkollektiv (Frankfurth am Main: Suhrkamp, 1980).
[2] Thomas Kuhn, “The Structure of Scientific Revolutions,” in International Encyclopedia of Unified Science, 2(2), 1962.
[3] Paul Feyerabend, Science in a Free Society (London: Verso Books, 2018).
[4] Jouni-Matti Kuukkanen, “Making Sense of Conceptual Change,” History and Theory, 47/3 (2008), 351-372.
[5] Shenghui Wang, Stefan Schlobach, and Michel Klein, “Concept Drift and How to Identify it,” Journal of Web Semantics, 9/3 (2011), 247-265.
[6] These limitations in the “horizon of understanding” are somehow related to Gadamer’s philosophical hermeneutics. See Hans-Georg Gadamer, Truth and Method, Eng. trans. by J. Weinsheimer, D.G. Marshall DG (London: Continuum, 2004).
[7] Stefano Borgo, Roberta Ferrario, Aldo Gangemi, Nicola Guarino, Claudio Masolo, Daniele Porello, Emilio M. Sanfilippo, and Laure Vieu, “Dolce: A Descriptive Ontology for Linguistic and Cognitive Engineering,” Applied Ontology, 17/1 (2022), 5-69.
[8] Aldo Gangemi and Valentina Presutti, “Ontology Design Patterns,” Handbook on Ontologies (Berlin: Springer, 2009), 221-243.
[9] John Dewey, Art as Experience, LW, Vol. 10 (Carbondale and Edwardsville: Southern Illinois University Press, 1989).
[10] Arthur C. Danto, The Transfiguration of the Commonplace (Cambridge, MA: Harvard University Press, 1981).
[11] Frank Sibley, Approach to Aesthetics. Collected Papers on Philosophical Aesthetics, ed. John Benson et al. (Oxford: Oxford University Press, 2001).
[12] Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu, Unifying Large Language Models and Knowledge Graphs: A roadmap, IEEE Transactions on Knowledge and Data Engineering, 2024.
[13] Pan, Shirui, et al. “Unifying large language models and knowledge graphs: A roadmap.” IEEE Transactions on Knowledge and Data Engineering 36.7 (2024): 3580-3599.
[14] Aldo Gangemi, Valentina Presutti. “Ontology design patterns.” Handbook on ontologies. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009. 221-243.
[15] Aldo Gangemi and Silvio Peroni, “The Information Realization Pattern,” Ontology Engineering with Ontology Design Patterns (Amsterdam: IOS Press, 2016), 299-312.
[16] Silvio Peroni and David Shotton. “Fabio and Cito: Ontologies for Describing Bibliographic Resources and Citations,” Journal of Web Semantics, 17 (2012), 33-43.
[17] Karen Coyle, “FRBR, Twenty Years On,” Cataloging & Classification Quarterly, 53/3-4 (2015), 265-285.
[18] Alexandru Constantin, Silvio Peroni, Steve Pettifer, David Shotton, and Fabio Vitali, The Document Components Ontology (Doco), Semantic Web, 7/2 (2016), 167-181.
[19] Stefano Borgo, Roberta Ferrario, Aldo Gangemi, Nicola Guarino, Claudio Masolo, Daniele Porello, Emilio M. Sanfilippo, and Laure Vieu, “DOLCE: A descriptive ontology for linguistic and cognitive engineering.” Applied ontology 17.1 (2022): 45-69.
[20] Stefano De Giorgis, Aldo Gangemi, Alessandro Russo, “Neurosymbolic graph enrichment for grounded world models”, Information Processing and Management, 62 (4), 2025.